mysql
-
巧用Navicat for MySQL的快捷键-navicat教程-学派吧
本文章给大家带来的内容是关于巧用Navicat for MySQL的快捷键,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 巧妙地使用 Navicat for MySQL 快捷键,可以大大提高工作效率,本篇经验将分类介绍 Navicat for MySQL 快捷键。 ctrl+q 打开查询窗口 ctrl+/ 注释sql语句 ctrl+shif…
-
navicat for mysql下载安装以及简单的使用教程-navicat-学派吧
本篇文章主要介绍了navicat for mysql下载安装以及简单的使用,有对novicat for mysql 感兴趣的小伙伴可以参考一下 一:下载Navicat for MySQL 下载地址:http://www.php.cn/xiazai/gongju/757 二:安装Navicat for MySQL 运行 → 下一步 → 点击“我同意” → 选择…
-
MongoDB提升性能的方法教程-mysql教程-学派吧
本篇文章给大家带来的内容是关于MongoDB提升性能的方法总结,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 MongoDB 是高性能数据,但是在使用的过程中,大家偶尔还会碰到一些性能问题。MongoDB和其它关系型数据库相比,例如 SQLServer 、MySQL 、Oracle相比来说,相对较新,很多人对其不是很熟悉,所以很多开发、DB…
-
mysql数据库中影响性能因素(附数据库架构案例)-mysql教程-学派吧
本篇文章给大家带来的内容是mysql数据库中影响性能因素的讲解(附数据库架构案例),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 关于数据库性能的故事 面试时多多少少会讲到数据库上的事情,“你对数据库的掌握如何?”,什么时候最考验数据库的性能,答应主要方面上讲就是大数据量的读写时,而电商类的大促活动就是考验各自的数据库性能的时候啦。 对于w…
-
MYSQL查询怎么优化?mysql查询优化的方法教程-mysql教程-学派吧
本篇文章给大家带来的内容是关于python中进程池的简单实现代码,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助 1. 在所有用于where,order by和group by的列上添加索引 索引除了能够确保唯一的标记一条记录,还能是MySQL服务器更快的从数据库中获取结果。索引在排序中的作用也非常大。 Mysql的索引可能会占据额外的空间,并…
-
mysql的20条优化教程-mysql教程-学派吧
本篇文章给大家带来的内容是关于mysql的优化总结,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 前言 现如今,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显。所以,我整理了MySQL优化的几点建议,希望这些优化技巧对您有用,总结不到的,欢迎大家补充。 SQL执行慢的原因 网络速度慢,内存不足,I/O吞吐量小,磁盘空…
-
lnmp、lamp、lnmpa一键安装包 安装使用方法
这个脚本是使用shell编写,为了快速在生产环境上部署lnmp/lamp/lnmpa(Linux、Nginx/Tengine/OpenResty、MySQL/MariaDB/Percona、PHP),适用于CentOS 6~7(包括redhat)、Debian 6~8、Ubuntu 12~16的32位和64位。 脚本特性 持续不断…
-
MySQL5.7版本sql_mode=only_full_group_by问题解决教程-网络运维
问题: MySQL数据库迁移到MySQL5.7版本后,出现如下报错: 原因分析:MySQL5.7版本默认设置了 mysql sql_mode = only_full_group_by 属性,导致报错。 解决办法: 1、打开MySQL数据库控制台 执行全局sql语句: set @@sql_mode= ‘STRICT_TRANS_TABLES,N…
-
fastcgi分离和lamp虚拟主机部署wordpress和discuzx教程
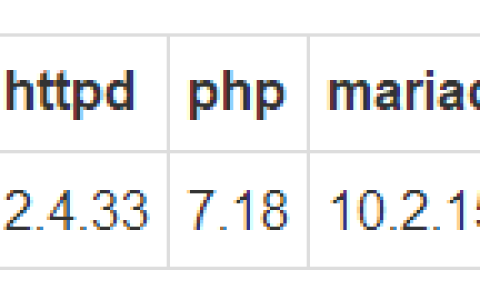
lamp架构wordpress和discuzx教程 背景 虚拟主机 fastcgi 部署流程 部署架构 环境 架构图 编译软件 安装开发环境和必要的包 编译httpd 编译php 安装mariadb 配置文件修改 修改httpd主机 修改fast-cgi主机 配置mysql 宿主机的hosts文件修改 安装wordpress和Discuzx 背景 虚拟主机 …
-
mysql关于注入的防范及总结教程
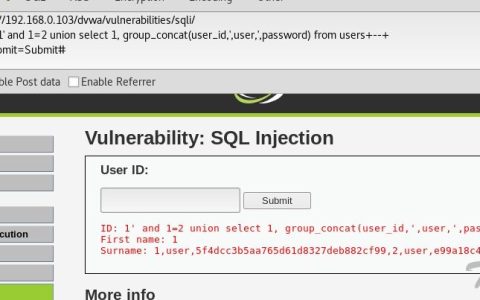
今天给大家带来一篇关于mysql数据库的注入总结教程 基础知识 什么是SQL注入 什么是Mysql MySQL手工注入 手工注入流程 判断注入点 判断查询的字段数 确定回显位 获取信息函数 获取数据库名 获取表名 获取列名 获取数据 写shell 各位大佬。。。这篇文章是个人再练习注入的时候自己总结出来的一部分经验,步骤确实很简单,百度上面确实也能搜的到相关…
-
mysqldump 参数和使用方法及资料说明
前言 mysqldump是mysql用于转存储数据库的实用程序。它主要产生一个SQL脚本,其中包含从头重新创建数据库所必需的命令CREATE TABLE INSERT等。 1. 常用参数 2. mysqldump 默认参数 3. mysqldump 常用方法 mysqldump是MySQL数据库自带的一款命令行工具,mysqldump属于单线程,功能是非常强…
-
Ubuntu+nginx搭建wordpress的教程-WP搭建
一. 前言 二. 接下来就是搭博客的过程 三、大功告成 一. 前言 开学之初,我发现Azure上有一个100刀的学生优惠。但在领取这个优惠之后,我却一直没有使用的机会,一是自己不会用,二是没有多余的时间。现在等来了放假,终于可以好好搞一搞了。:joy: 这次搭博客可谓是踩了不少坑: 百度的教程基本上都是废的,只有谷歌的英文教程才是能用的,好气啊 apache…
-
nginx+php-fpm搭建wordpress-WP搭建教程
1. 准备 LNMP 环境 2. 安装wordpress 3. 配置 一开始搭建的hexo博客,hexo博客有个缺点,他是用nodejs的服务器,不太稳定,服务器经常挂。所以最后还是决定用nginx+php-fpm搭建一个wordpress站点,这样网站就比较稳定。废话不多说,直接进入主题。 我是用的centos的服务器,下面的一些个命令也是centos的命…
-
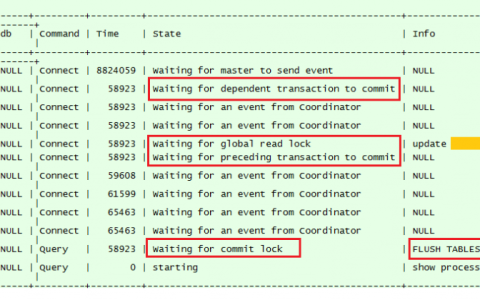
MySQL 5.7并发复制和mysqldump相互阻塞引起的复制延迟-Linux运维日志
有需要服务器方面的需求和咨询,可以联系博主 QQ 7271895 本来MySQL BINLOG和SHOW PROCESSLIST命令属于八竿子打不着的两个事务,但在最近故障排查中,发现主库和从库已经存在很严重的复制延迟,但从库上显示slave_behind_master值为0,复制SQL线程与备份线程之间相互阻塞,但未报死锁 在从库上执行SHOW PROCE…