
win2008 R2 WEB服务器安全设置指南之组策略与用户设置详解教程-windows教程-学派吧
这篇文章主要介绍了win2008 R2 WEB 服务器安全设置指南之组策略与用户设置,需要的朋友可以参考下 通过优化设置组策略、对系统默认的管理员、用户进行重命名、创建陷阱帐户等措施来提高系统安全性。 接上篇,我们已经改好了远程连接端口,已...
这篇文章主要介绍了win2008 R2 WEB 服务器安全设置指南之组策略与用户设置,需要的朋友可以参考下 通过优化设置组策略、对系统默认的管理员、用户进行重命名、创建陷阱帐户等措施来提高系统安全性。 接上篇,我们已经改好了远程连接端口,已...
这篇文章主要介绍了win2008 r2安装SQL SERVER 2008 R2 不能打开1433端口设置方法,需要的朋友可以参考下 服务器:WINDOWS SERVER 2008 R2 SQL:SQL SERVER 2008 R2 背景:同...

【腾讯云】3年轻量2核2G4M 低至1.7折,仅需368元!
在Win10系统中如何设置打开自动搜索网络?本文将提供打开自动搜索网络的方法供大家了解。 打开自动搜索网络: 1、返回到win10系统的传统桌面位置,单击打开win10系统的开始菜单,然后从开始菜单中点击选择设置选项。 2、点击选择其中过的...
首先,来查看下系统当前都开放了什么端口,怎样查看呢?调出cmd命令行程序,输入命令”netstat -na“,可以看到。 接着,可以发现当前系统开放了135、445以及5357端口,而且从状态看都处于监听状态”Listeni...
本篇文章给大家带来的内容是关于Navicat查看MySQL日志的方法教程(图),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 1、使用Navicat服务器监控工具 2、打开日志开关 右边参数设置变量"log&qu...
本篇文章给大家带来的内容是关于Navicat连接MySQL8.0的方法(有效),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 今天下了个 MySQL8.0,发现Navicat连接不上,总是报错1251; 原因是MySQL8...
本篇文章给大家带来的内容是关于navicat中对数据库操作的方法介绍,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 navicat我觉得做程序的基本上都会用,它方便,快捷,直观等,优点很多,这也是我写这篇文章的原因。以前我...
本篇文章给大家带来的内容是关于navicat如何为表添加索引?(图文),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 navicat 为表添加索引 分析常用的查询场景,为字段添加索引,增加查询速度。 可以添加单列索引,可以...
为了减少开发人员的错误操作,可以设置权限来进行控制,通过为MySQL服务器建立不同的用户,并为用户赋予不同的权限,来达到目标。这篇文章就给大家介绍怎么设置Navicat数据库的操作权限,需要的朋友可以参考一下。1 以下内容为详细设置步骤。 ...
本文章给大家带来的内容是关于巧用Navicat for MySQL的快捷键,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 巧妙地使用 Navicat for MySQL 快捷键,可以大大提高工作效率,本篇经验将分类介绍 N...
本篇文章主要介绍了navicat for mysql下载安装以及简单的使用,有对novicat for mysql 感兴趣的小伙伴可以参考一下 一:下载Navicat for MySQL 下载地址:http://www.php.cn/xia...
本篇文章给大家带来的内容是关于Redis与Memcached有何区别 ?redis和Memcached的区别比较,有一定的参考价值,有需要的朋友可以参考一下, memcached和redis,作为近些年最常用的缓存服务器,相信大家对它们再熟...
本篇文章给大家带来的内容是关于CPU资源和可用内存大小对数据库性能有何影响?有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助 前言 可能影响到数据库性能的几个点,其一就是服务器硬件,也是本节要说的CPU与可用内存。 引入 当热数...
本篇文章给大家带来的内容是mysql数据库中影响性能因素的讲解(附数据库架构案例),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 关于数据库性能的故事 面试时多多少少会讲到数据库上的事情,“你对数据库的掌握如何?”,什么时...
本篇文章给大家带来的内容是关于python中进程池的简单实现代码,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助 1. 在所有用于where,order by和group by的列上添加索引 索引除了能够确保唯一的标记一条记录...
本篇文章给大家带来的内容是关于Redis是什么?有哪些应用场景?有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 一丶Redis介绍 1 Redis是一个开源的 key—value型 单线程 数据库,支持string、list...
本篇文章给大家带来的内容是关于Redis的事务操作的命令与执行操作(代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 序1 本文主要研究一下redis的事务操作 命令 multi与exec 命令行 127.0.0.1:...
本篇文章给大家带来的内容是关于如何快速简单的优化快照使用成本,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 如何优化快照使用成本 快照推荐使用场景 快照作为一种便捷高效的数据保护服务手段,推荐应用于以下业务场景中: 系统盘...




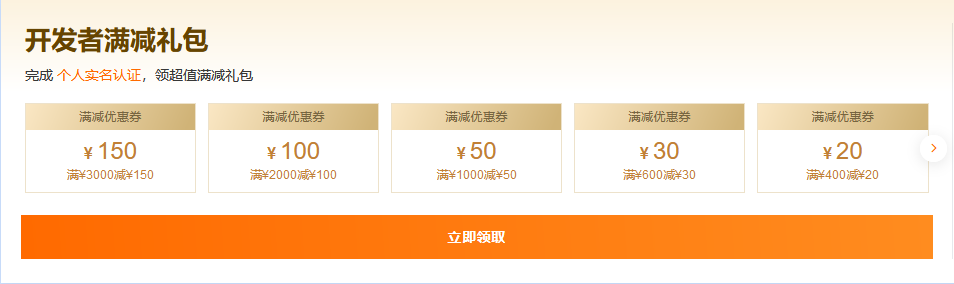
每天两场(上午10:00,下午15:00),上云首选云服务器限量抢购,助力低成本上云
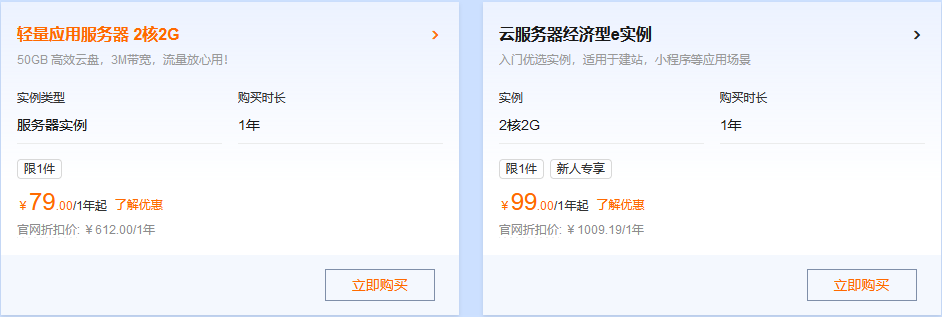
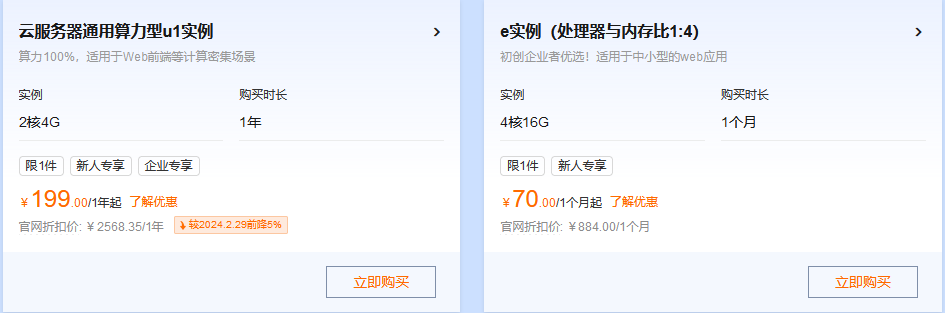
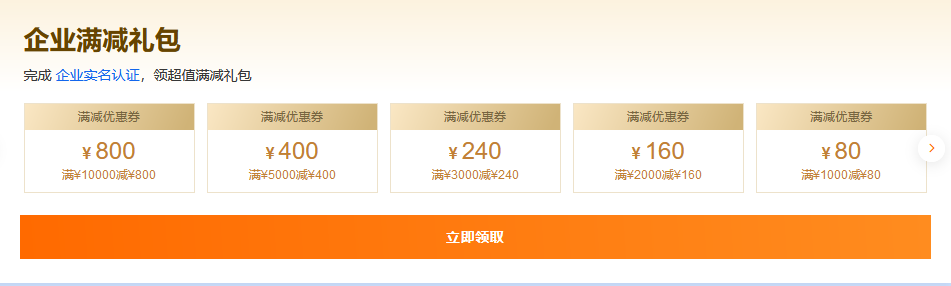
阿里云200+款云产品折上再折,满足多样场景的上云需求 活动规则
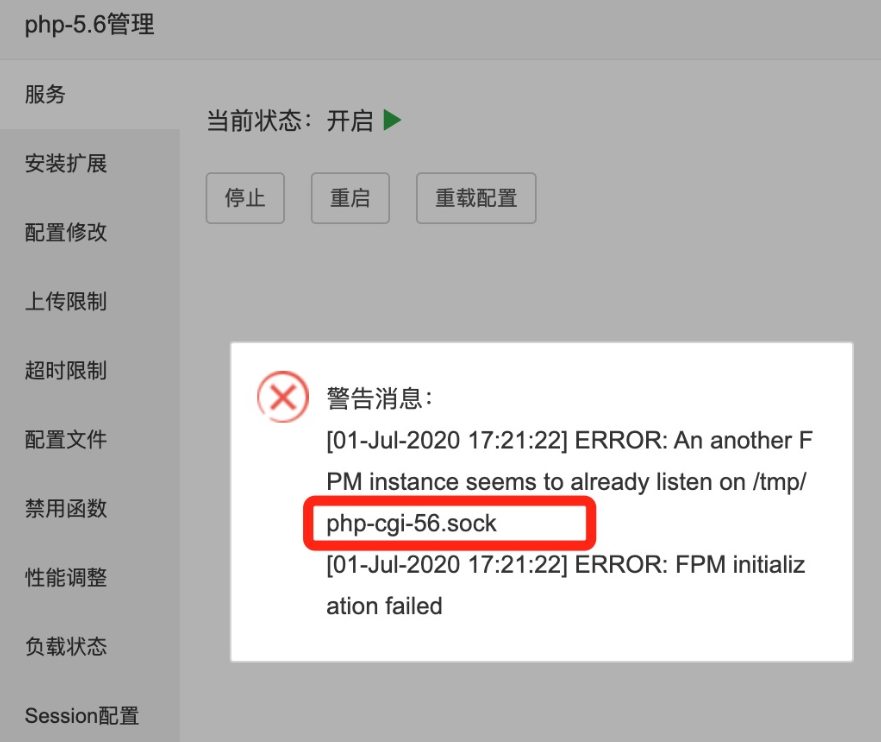
解决方法:将这个路径下的文件删除后再重启 /tmp/php-cgi-56.sock
进入ssh 执行以下命令再重启php
rm -f /tmp/php-cgi-56.sock具体不同的php版本,需要将以上命令的56更换为具体报错的php版本号,不能生搬硬套哦
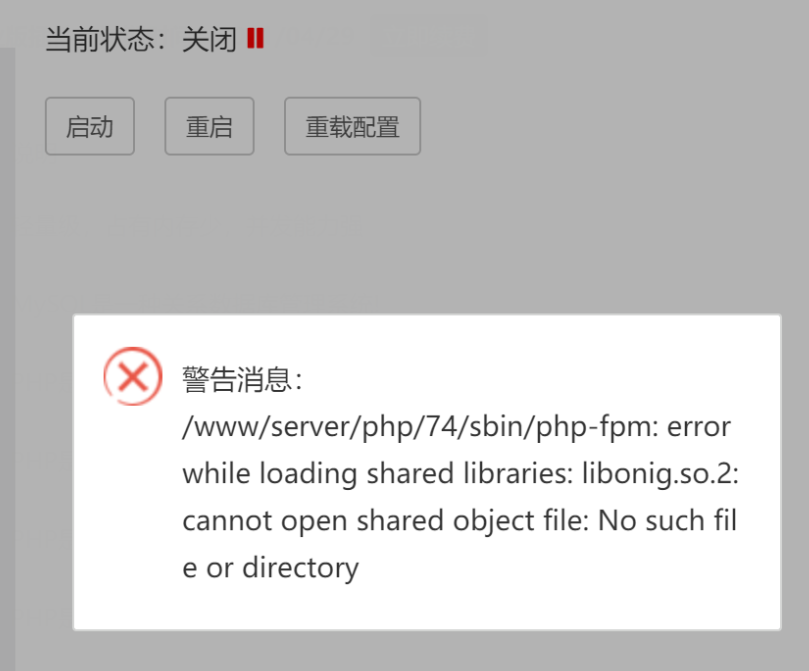
解决方法:进入ssh 执行这条命令 再尝试启动
yum install libsodium-devel sqlite-devel oniguruma-devel libwebp-devel libvpx-devel -y
解决方法:
/etc/init.d/php-fpm-72 stop /etc/init.d/php-fpm-72 start然后再启动试试
注意:以上的72,为php版本号,哪个版本的php启动不了,就将以上命令的72改为对应版本号
阿里云上云优惠聚集地,新人专享优惠价格,可叠加专享代金券购买价格更低。
折扣卷领取:https://www.aliyun.com/minisite/goods?userCode=fa2nbd3s


(1)折扣券不可用于购买产品提货券;
(2)99计划产品暂不支持折扣补贴券抵扣使用;
(3)折扣券必须先领取成功后方可使用;
(4)PC或者无线端订单最终是否支持折扣券请以下单页面实际情况为准;
(5)用户领取的折扣券有效期为15天,有效期内下单购买有效,15天后券自动失效作废。
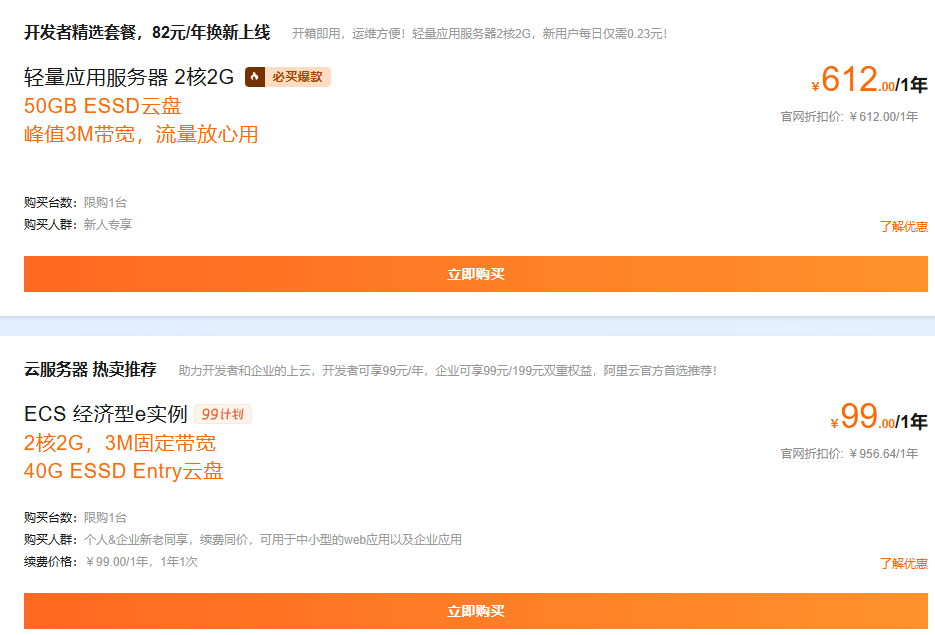
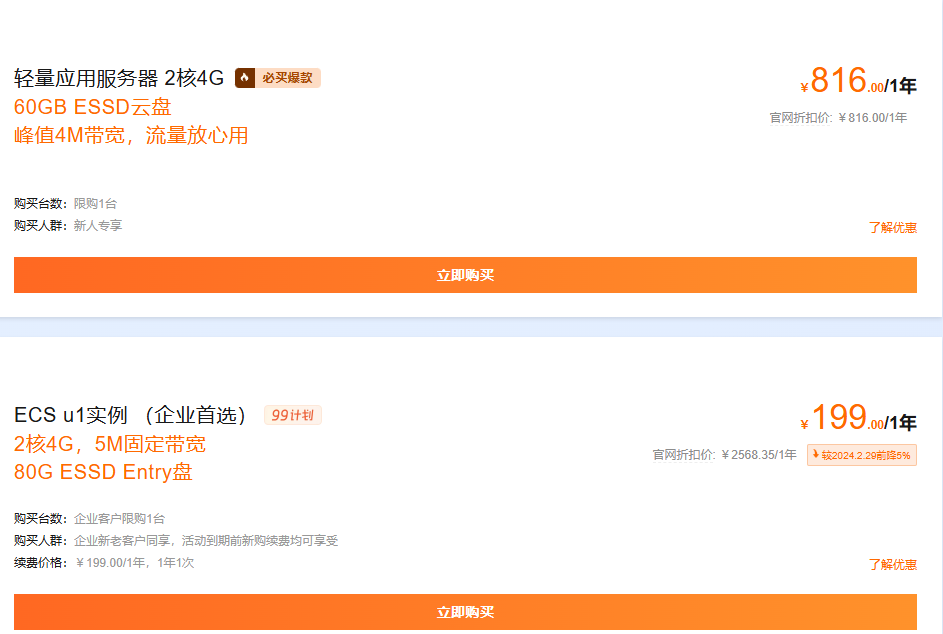
 同价续费:参与本专区活动,享新购续费同价1次
同价续费:参与本专区活动,享新购续费同价1次

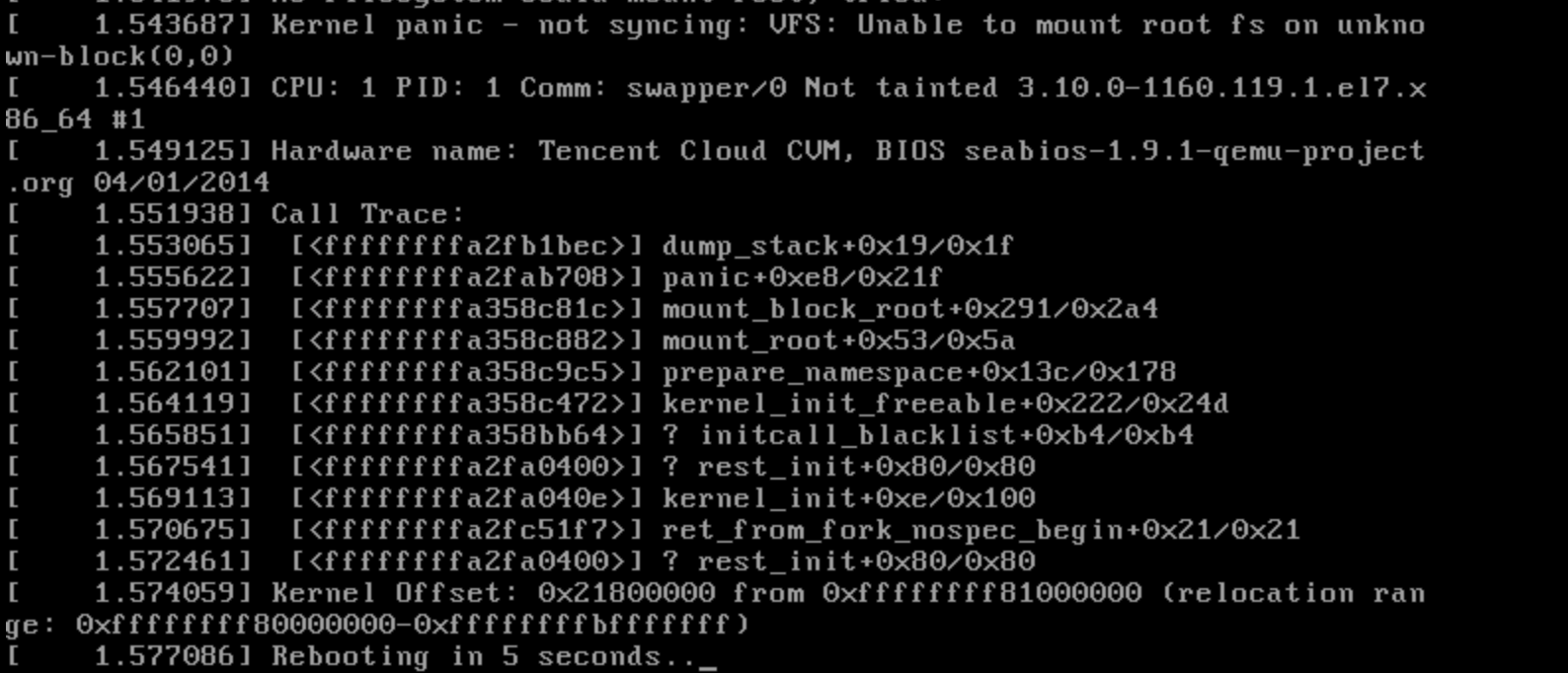
1. 系统启动失败,输出 VFS: Unable to mount root fs on unknow-block 可能是 initramfs 或 initrd 有问题,需要重新 生成 initramfs 或 initrd:。如下图所示:

mkdir -p /mnt/vm1
mount /dev/vda1 /mnt/vm1
mount -o bind /dev /mnt/vm1/dev
mount -o bind /dev/pts /mnt/vm1/dev/pts
mount -o bind /proc /mnt/vm1/proc
mount -o bind /run /mnt/vm1/run
mount -o bind /sys /mnt/vm1/sys
chroot /mnt/vm1 /bin/bash3.执行以下命令,重新生成 initramfs/initrd。
wget http://mirrors.tencentyun.com/install/cts/linux/cvmrescue_main.sh && chmod +x cvmrescue_main.sh && ./cvmrescue_main.sh -m rebuild_initramfs碰到域名解析失败的可以在 /etc/hosts 中配置 hosts 169.254.0.3 mirrors.tencentyun.com。
4.输出如下,表示 initramfs 或 initrd 新建成功。

5.参见 使用救援模式,退出救援模式,启动系统。
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文介绍如何使用iostat、iotop工具查看I/O负载情况。
iotop是一个用来监视磁盘I/O使用状况的top类工具,可以从进程纬度查看磁盘IO负载。
执行如下命令,安装iotop。
yum install iotop执行如下命令,查看I/O负载。
iotop -k -n 5 -d 3-b:记录到日志。
-k:以KB为单位显示。
-n:统计次数。
-d:统计时间间隔。
显示结果如下。
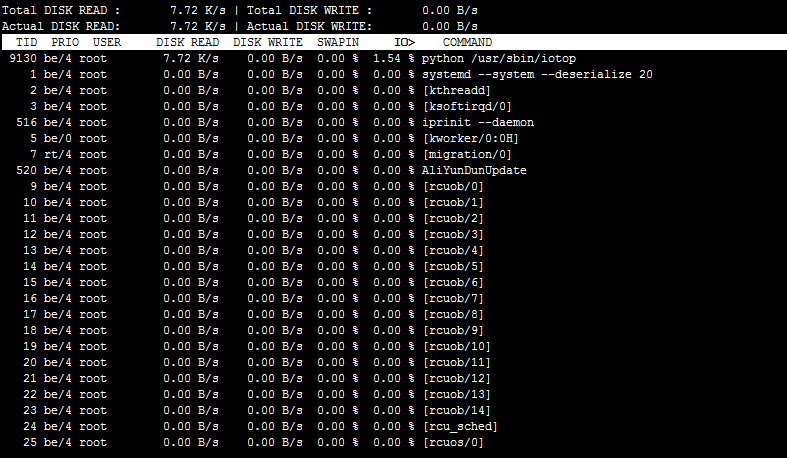
显示结果参数说明如下,更多参数说明,可执行iotop -h查询。
DISK READ:该进程读I/O带宽。
DISK WRITE:该进程写I/O带宽。
SWAPIN:磁盘的交换使用率。
IO:该进程的 I/O 利用率,包含磁盘和交换。
使用iotop排查分析,发现kjournald进程占用了大量I/O资源。
该问题通常是由于.ext3文件系统设置的Journal size太小导致。
kjournald进程是ext3文件系统进行I/O数据操作的内核进程,它在向磁盘内写入和读取数据时占用CPU和内存资源。当循环的向ext3文件系统写数据时,会使Journal size不断增大,到达设置的Journal size时,就会出现该问题。
远程连接Linux系统的ECS实例。
具体操作,请参见连接方式概述。
执行如下命令,查看相应分区的Journal size大小。
dumpe2fs /dev/xvda1 | grep Journal/dev/xvda1请替换为实际的分区。
系统显示类似如下,表示/dev/xvda1分区的Journal size为128M。
dumpe2fs 1.42.9 (28-Dec-2013)
Journal inode: 8
Journal backup: inode blocks
Journal features: journal_incompat_revoke
Journal size: 128M
Journal length: 32768
Journal sequence: 0x00010ffb
Journal start: 10953执行如下命令,修改Journal size大小。
mke2fs -J size=400 /dev/xvda1 请根据业务需要,修改size大小,/dev/xvda1请替换为实际的分区。
4K对齐指将符合4K扇区定义格式化过的硬盘,按照4K扇区的规则写入数据。4K对齐可以使簇与扇区相对应,保证了磁盘读写效率,以提高I/O性能。
本操作介绍如何通过以下脚本对磁盘进行格式化并自动配置4K对齐。
运行此脚本会自动格式化所有数据盘,如果非新购数据盘,请在操作前,确认已对相关数据盘进行数据备份。具体操作,请参见创建一个云盘快照。
使用root用户远程连接Linux系统的ECS实例。
具体操作,请参见连接方式概述。
下载auto_fdisk.zip压缩包后解压,将解压后脚本并上传到目标服务器。
依次执行如下命令,为脚本添加执行权限,然后运行脚本。
chmod +x ./auto_fdisk.sh
./auto_fdisk.sh