
MySQL中如何将字符串转为base64编码?-mysql教程-学派吧
在MySQL中,TO_BASE64()函数将字符串转换为以base-64编码的字符串并返回结果。(相关推荐:《MySQL教程》) 语法 TO_BASE64(str) 其中str是需要编码的字符串。 例1 -基本用法 下面是一个例子来演示基本...
在MySQL中,TO_BASE64()函数将字符串转换为以base-64编码的字符串并返回结果。(相关推荐:《MySQL教程》) 语法 TO_BASE64(str) 其中str是需要编码的字符串。 例1 -基本用法 下面是一个例子来演示基本...
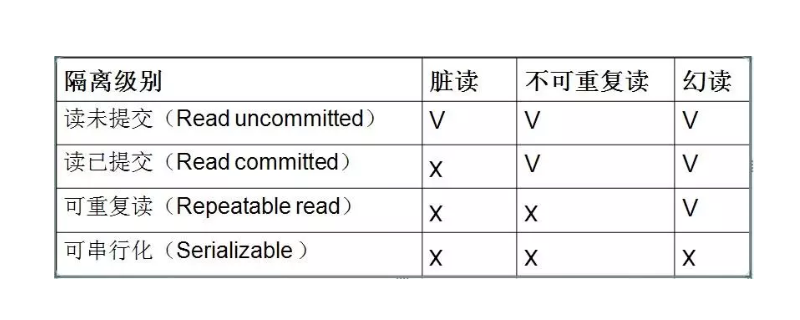
数据库的四个级别分为:读取未提交内容,读取提交内容,可重读以及可串行化。但隔离级别也会造成脏读,不可重复读以及幻读等问题 【推荐课程:MySQL教程】 数据库隔离的四个级别分别为: Read Uncommitted(读取未提交内容) 在该隔...

【腾讯云】3年轻量2核2G4M 低至1.7折,仅需368元!
mysql中索引类型有:最基本的没有限制的普通索引,索引列的值必须唯一的唯一索引,主键索引,多个字段上创建的组合索引以及用来查找文本中的关键字的全文索引 【推荐课程:MySQL教程】 MySQL中的索引类型有以下几种 普通索引 唯一索引 主...
本篇文章给大家带来的内容是关于mongodb查询表字段、进行字符串截取以及更新的方法,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 update() 方法用于更新已存在的文档。语法格式如下: db.collection.u...
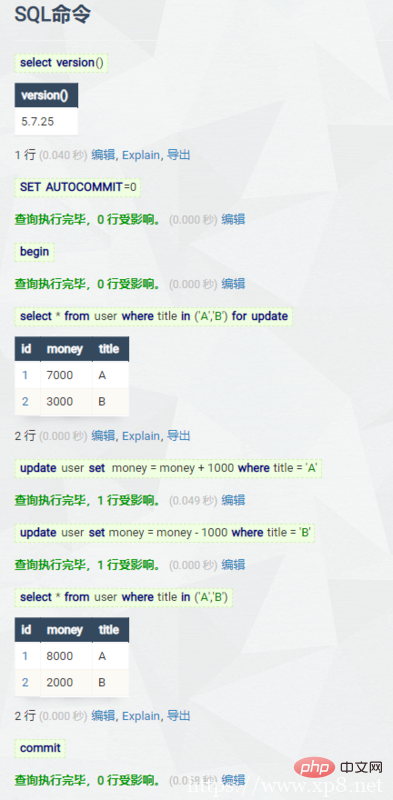
本篇文章给大家带来的内容是关于MySQL和Redis事务的比较(图文),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 简言:一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致...
MySQL包含了很多函数和运算符,可以帮助我们处理数据。下面我们就给大家整理出MySQL中可用的数学函数,希望对需要的朋友有所帮助! ABS()返回给定值的绝对值。 ACOS()返回数字的反余弦值。 ASIN()返回数字的反正弦值。 ATA...
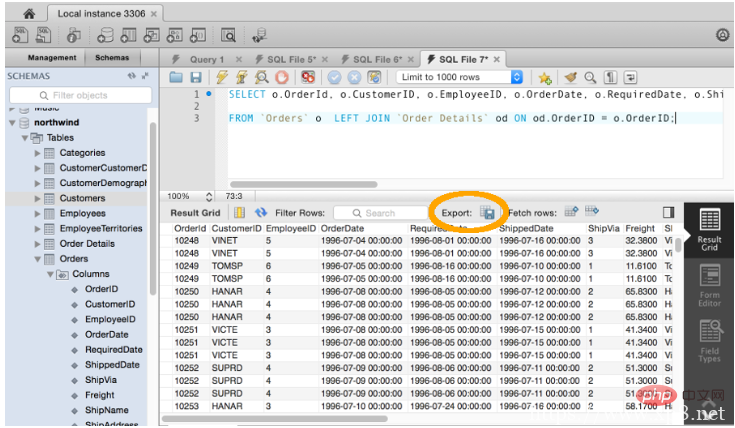
你可以使用MySQL Workbench运行一个查询,然后将该查询的结果导出到一个文件中。(相关推荐:《MySQL教程》) 步骤: 1、运行查询 2、单击“Results Grid”菜单栏上的“Export” 如下截图: 注意:MySQL ...

MySQL更新语句也就是MySQL中的update语句,当我们需要更新或者修改表中的数据时,就会使用这个update语句,下面我们就来看一下mysql更新语句的具体写法。 MySQL中update语句用于更新表中的现有数据。亦可用UPDAT...
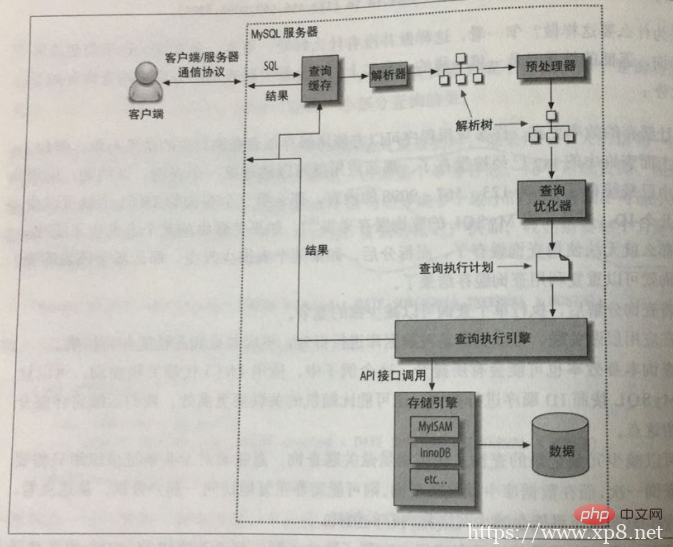
本篇文章给大家带来的内容是关于MySQL执行过程以及查询缓存的详细介绍,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 MySQL执行一个查询过程:当我们向MySQL发送一个请求的时候,MySQL到底做了什么: 1.客户端发...

MySQL中的存储过程指的是存储在数据库中的SQL语句集合,当创建好存储过程后在运行时提供所需参数,存储过程就可以以代码指定的方式使用参数执行并返回值 在MySQL中提供了创建存储过程的能力。存储过程是MySQL以及其他数据库管理系统中的强...

本篇文章主要给大家介绍mysql索引原理,希望对需要的朋友有所帮助!(相关推荐:《mysql教程》) 索引的目的 索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再...
本篇文章给大家带来的内容是关于MySQL中EXPLAIN解释命令的介绍(附示例),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 1 EXPLAIN概念 EXPLAIN会向我们提供一些MySQL是执行sql的信息: EXPL...
Oracle的MySQL是一个流行的基于结构化查询语言(SQL)的开源关系数据库管理系统。它经常与PHP一起使用,以增强网站的功能。PHP预装在Mac电脑上,而MySQL没有。 当您创建和测试需要MySQL数据库的软件或网站时,在您的计算机...
本篇文章主要给大家介绍在mysql中如何解码base64编码的字符串,那么我们可以通过FROM_BASE64()函数来实现解码。 在MySQL中,FROM_BASE64()函数解码一个base-64编码的字符串并返回结果。更具体地说,它接受...

Linux tail命令显示一个或多个文件或管道数据的最后一部分(默认为10行);可用于实时监控文件更改。下面本篇文章就来就来给大家介绍一下如何使用Linux tail命令,希望对大家有所帮助。 Linux tail命令 tail命令显示一...

cPanel / WHM是一个基于Web的控制面板,用于管理完整的Linux操作系统。所有cPanel帐户都是使用一个主域创建的。本篇文章将介绍更改cPanel用户主域的文档。 必须具有root shell访问权限才能更改cPanel中的主...

C是一种用于开发系统软件的强大编程语言。本篇文章将介绍关于通过命令行在Linux系统中运行C和C ++程序。在本篇文章中,我们使用GCC(GNU Compiler Collection)的’gcc’和’g...

Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和UNIX的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的UNIX工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以...




每天两场(上午10:00,下午15:00),上云首选云服务器限量抢购,助力低成本上云
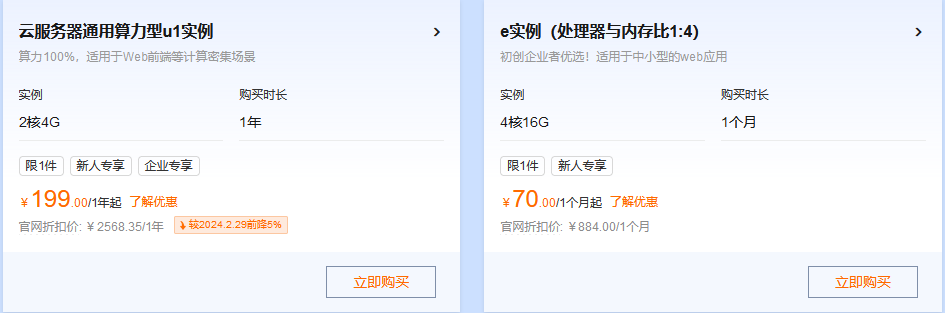
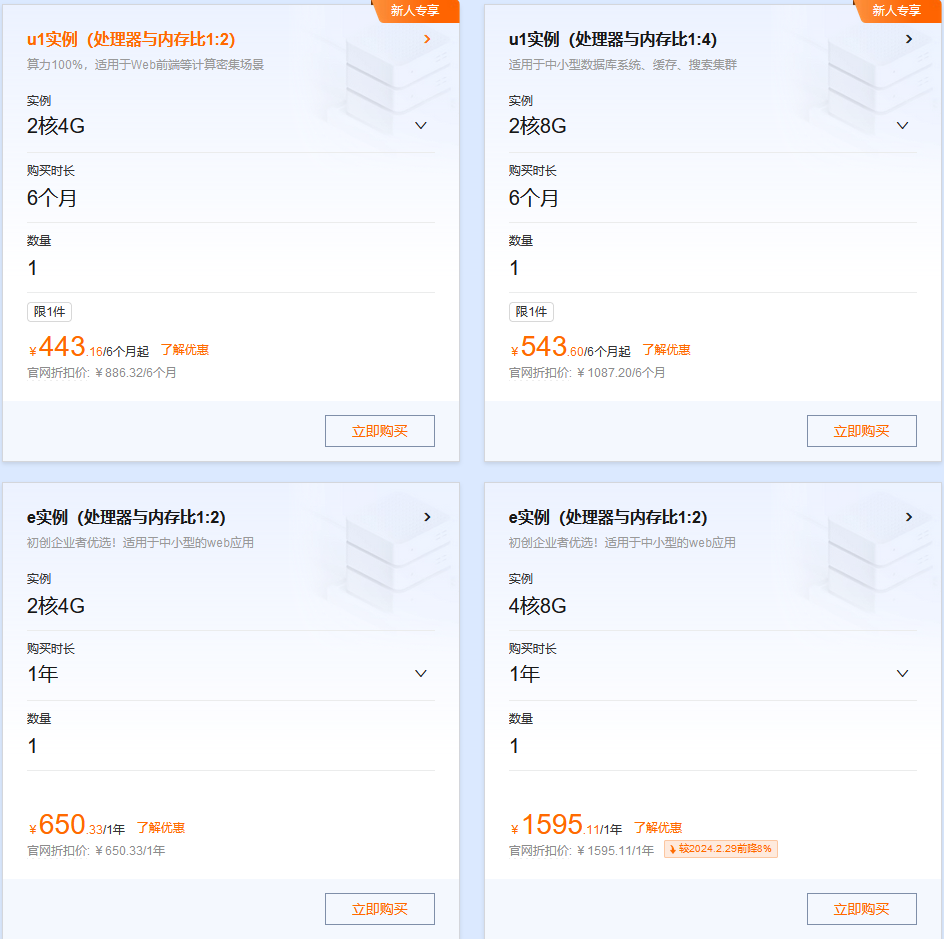
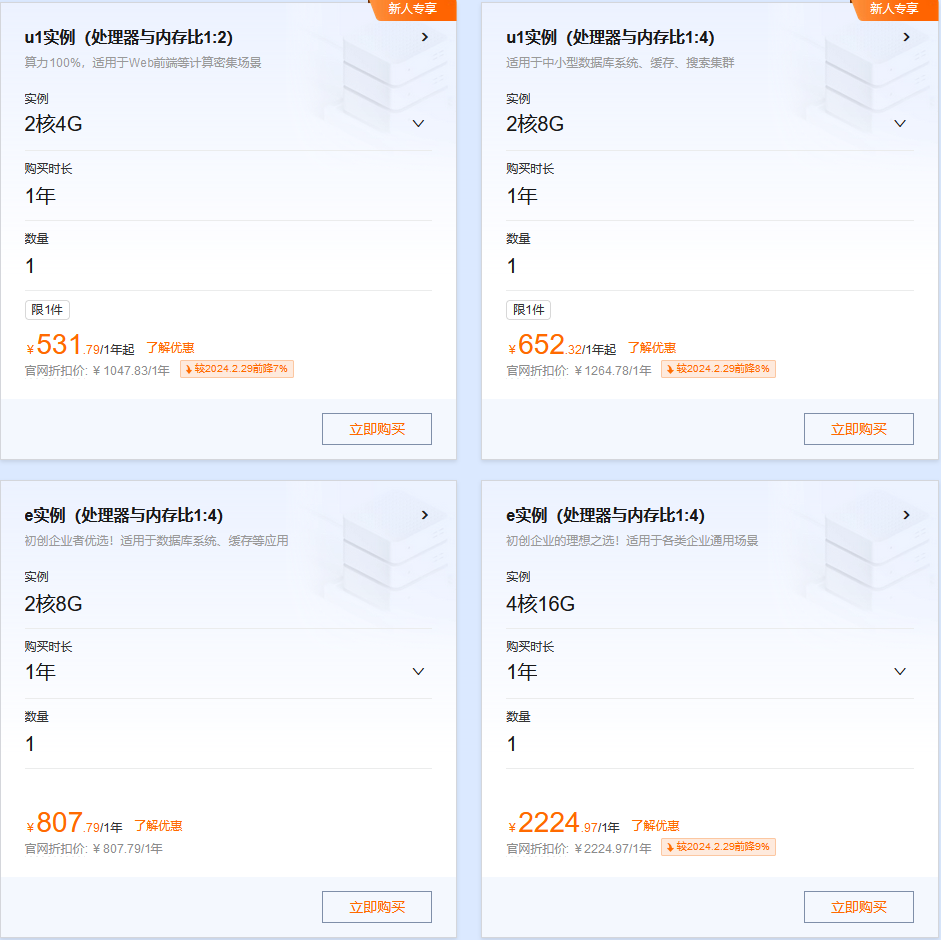
阿里云200+款云产品折上再折,满足多样场景的上云需求 活动规则
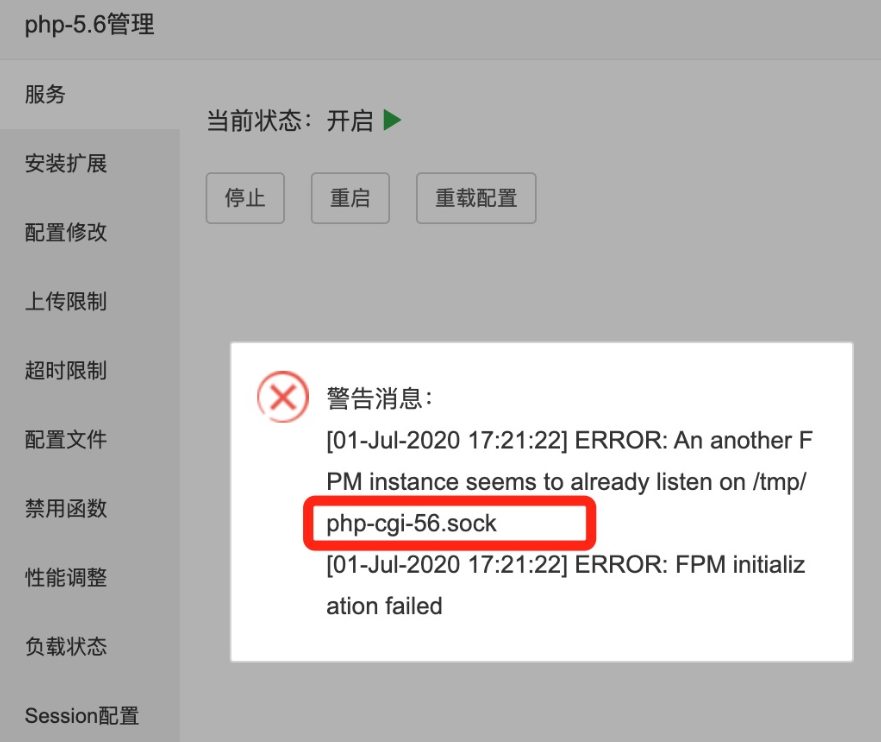
解决方法:将这个路径下的文件删除后再重启 /tmp/php-cgi-56.sock
进入ssh 执行以下命令再重启php
rm -f /tmp/php-cgi-56.sock具体不同的php版本,需要将以上命令的56更换为具体报错的php版本号,不能生搬硬套哦
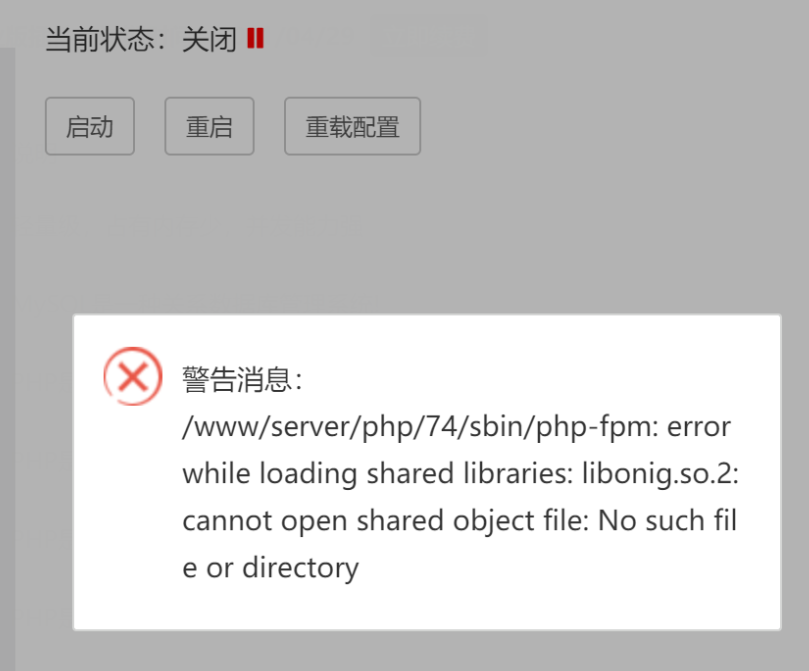
解决方法:进入ssh 执行这条命令 再尝试启动
yum install libsodium-devel sqlite-devel oniguruma-devel libwebp-devel libvpx-devel -y
解决方法:
/etc/init.d/php-fpm-72 stop /etc/init.d/php-fpm-72 start然后再启动试试
注意:以上的72,为php版本号,哪个版本的php启动不了,就将以上命令的72改为对应版本号
阿里云上云优惠聚集地,新人专享优惠价格,可叠加专享代金券购买价格更低。
折扣卷领取:https://www.aliyun.com/minisite/goods?userCode=fa2nbd3s


(1)折扣券不可用于购买产品提货券;
(2)99计划产品暂不支持折扣补贴券抵扣使用;
(3)折扣券必须先领取成功后方可使用;
(4)PC或者无线端订单最终是否支持折扣券请以下单页面实际情况为准;
(5)用户领取的折扣券有效期为15天,有效期内下单购买有效,15天后券自动失效作废。
 同价续费:参与本专区活动,享新购续费同价1次
同价续费:参与本专区活动,享新购续费同价1次

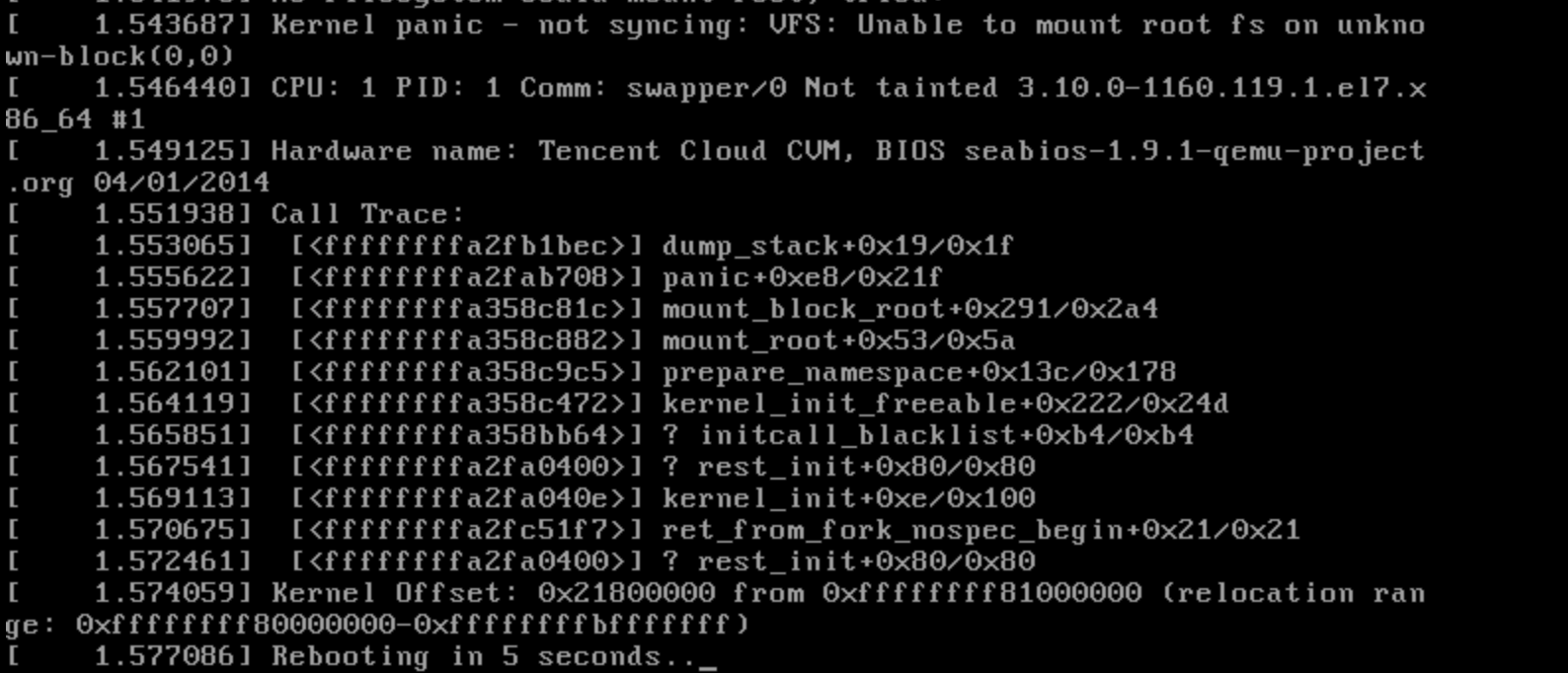
1. 系统启动失败,输出 VFS: Unable to mount root fs on unknow-block 可能是 initramfs 或 initrd 有问题,需要重新 生成 initramfs 或 initrd:。如下图所示:

mkdir -p /mnt/vm1
mount /dev/vda1 /mnt/vm1
mount -o bind /dev /mnt/vm1/dev
mount -o bind /dev/pts /mnt/vm1/dev/pts
mount -o bind /proc /mnt/vm1/proc
mount -o bind /run /mnt/vm1/run
mount -o bind /sys /mnt/vm1/sys
chroot /mnt/vm1 /bin/bash3.执行以下命令,重新生成 initramfs/initrd。
wget http://mirrors.tencentyun.com/install/cts/linux/cvmrescue_main.sh && chmod +x cvmrescue_main.sh && ./cvmrescue_main.sh -m rebuild_initramfs碰到域名解析失败的可以在 /etc/hosts 中配置 hosts 169.254.0.3 mirrors.tencentyun.com。
4.输出如下,表示 initramfs 或 initrd 新建成功。

5.参见 使用救援模式,退出救援模式,启动系统。
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文介绍如何使用iostat、iotop工具查看I/O负载情况。
iotop是一个用来监视磁盘I/O使用状况的top类工具,可以从进程纬度查看磁盘IO负载。
执行如下命令,安装iotop。
yum install iotop执行如下命令,查看I/O负载。
iotop -k -n 5 -d 3-b:记录到日志。
-k:以KB为单位显示。
-n:统计次数。
-d:统计时间间隔。
显示结果如下。
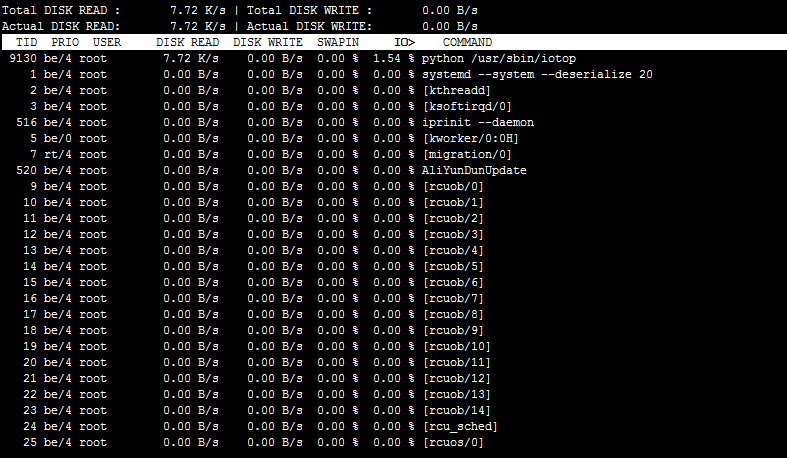
显示结果参数说明如下,更多参数说明,可执行iotop -h查询。
DISK READ:该进程读I/O带宽。
DISK WRITE:该进程写I/O带宽。
SWAPIN:磁盘的交换使用率。
IO:该进程的 I/O 利用率,包含磁盘和交换。
使用iotop排查分析,发现kjournald进程占用了大量I/O资源。
该问题通常是由于.ext3文件系统设置的Journal size太小导致。
kjournald进程是ext3文件系统进行I/O数据操作的内核进程,它在向磁盘内写入和读取数据时占用CPU和内存资源。当循环的向ext3文件系统写数据时,会使Journal size不断增大,到达设置的Journal size时,就会出现该问题。
远程连接Linux系统的ECS实例。
具体操作,请参见连接方式概述。
执行如下命令,查看相应分区的Journal size大小。
dumpe2fs /dev/xvda1 | grep Journal/dev/xvda1请替换为实际的分区。
系统显示类似如下,表示/dev/xvda1分区的Journal size为128M。
dumpe2fs 1.42.9 (28-Dec-2013)
Journal inode: 8
Journal backup: inode blocks
Journal features: journal_incompat_revoke
Journal size: 128M
Journal length: 32768
Journal sequence: 0x00010ffb
Journal start: 10953执行如下命令,修改Journal size大小。
mke2fs -J size=400 /dev/xvda1 请根据业务需要,修改size大小,/dev/xvda1请替换为实际的分区。
4K对齐指将符合4K扇区定义格式化过的硬盘,按照4K扇区的规则写入数据。4K对齐可以使簇与扇区相对应,保证了磁盘读写效率,以提高I/O性能。
本操作介绍如何通过以下脚本对磁盘进行格式化并自动配置4K对齐。
运行此脚本会自动格式化所有数据盘,如果非新购数据盘,请在操作前,确认已对相关数据盘进行数据备份。具体操作,请参见创建一个云盘快照。
使用root用户远程连接Linux系统的ECS实例。
具体操作,请参见连接方式概述。
下载auto_fdisk.zip压缩包后解压,将解压后脚本并上传到目标服务器。
依次执行如下命令,为脚本添加执行权限,然后运行脚本。
chmod +x ./auto_fdisk.sh
./auto_fdisk.sh