这篇文章主要介绍了win2008 R2 WEB 服务器安全设置指南之组策略与用户设置,需要的朋友可以参考下 通过优化设置组策略、对系统默认的管理员、用户进行重命名、创建陷阱帐户等措施来提高系统安全性。 接上篇,我们已经改好了远程连接端口,已经能拒绝一部份攻击了,但是这些设置还远远不够。在做以下安全时,必须确保你的服务器软件已经全部配置完毕,并且能正常使用,不然如果在安全设置后再安装软件的话,有可能会安装失败或发生其它错误,导致环境配置失败。 密码策略 系统密码的强弱直接关系到系统的安全,如果你的密码太简单,万一你的远程连接端口被扫到,那破解你的密码就是分分钟钟后了。所以,我们的系统密码必须要设置一个符合安全性要求的密码,如使用大小写英文、数字、特殊符号、长度不小于6位等措施来加强密码安全性。在Windows 2008以上系统中,系统提供了一个“密码策略”的设置,我们来设置它,先进入“本地安全策略”, 依次打开 "安全设置"—–"帐户策略"—–"密码策略"—–密码必须符合复杂性要求,启用. 审核策略 审核策略的作用就是万一有恶意用户在破解你的密码、登录你的系统,或者修改你的系统等事件,你可以及早发现并处理。 默认都是无审核,我们必须修改它,如下是我修改的审核策略, 己基本能捕捉所需信息,我们只要分析这些产生的日志,就能发现问题所在。 用户权限分配 这里主要是限制哪些用户可以使用远程连接登录到服务器,默认是Administrators组和Remote Desktop Users组,这二个组的成员都可以远程登录到服务器,而我们一般作为WEB服务器,用户不会太多,可能就只有一个管理员,所以就没必要指定组,直接指定用户就可以了。 修改系统用户和组 1、对系统默认用户名和用户组进行重命名,这里分二步。 ⑴、重命名默认管理员administrator和来宾帐户,如我就将administrator重命名为wobushiad,将guest重命名为wobushiguest, 以后登录服务器就要使用修改后的用户名wobushiad来登录。 ⑵、新建一个名为administrator,隶属于Guests组的用户,设置一个超级复杂的密码(在记事本里打一串字符包括大小写、数字、特殊符号复制进去,你自己无需记住此密码),并禁用帐户。这个帐户是一个陷阱帐户,我们自己并不会使用此帐户。 再修改默认管理员组administrators和Guest组, 安全选项 交互式登录: 不显示最后的用户名,启用 网络访问:不允许SAM帐户和共享的匿名枚举,启用 网络访问:不允许存储网络身份验证的密码和凭据,启用 网络访问:可远程访问的注册表路径,清空 网络访问:可远程访问的注册表路径和子路径,清空 以上就是win2008 R2 WEB服务器安全设置指南之组策略与用户设置详解(图)的详细内容,更多请关注学派吧其它相关文章!
这篇文章主要介绍了win2008 r2安装SQL SERVER 2008 R2 不能打开1433端口设置方法,需要的朋友可以参考下 服务器:WINDOWS SERVER 2008 R2 SQL:SQL SERVER 2008 R2 背景:同一个公司同一个局域网 网络可以ping通 但是不能连接服务器数据库 提示错误1326 前期设置: 经过前期设置都不行 telnet localhost 1433还是失败 后期设置: OK 到现在成功了。 以上就是win2008R2安装SQL SERVER 2008 R2不能打开1433端口的设置方法的图文详解的详细内容,更多请关注学派吧其它相关文章!
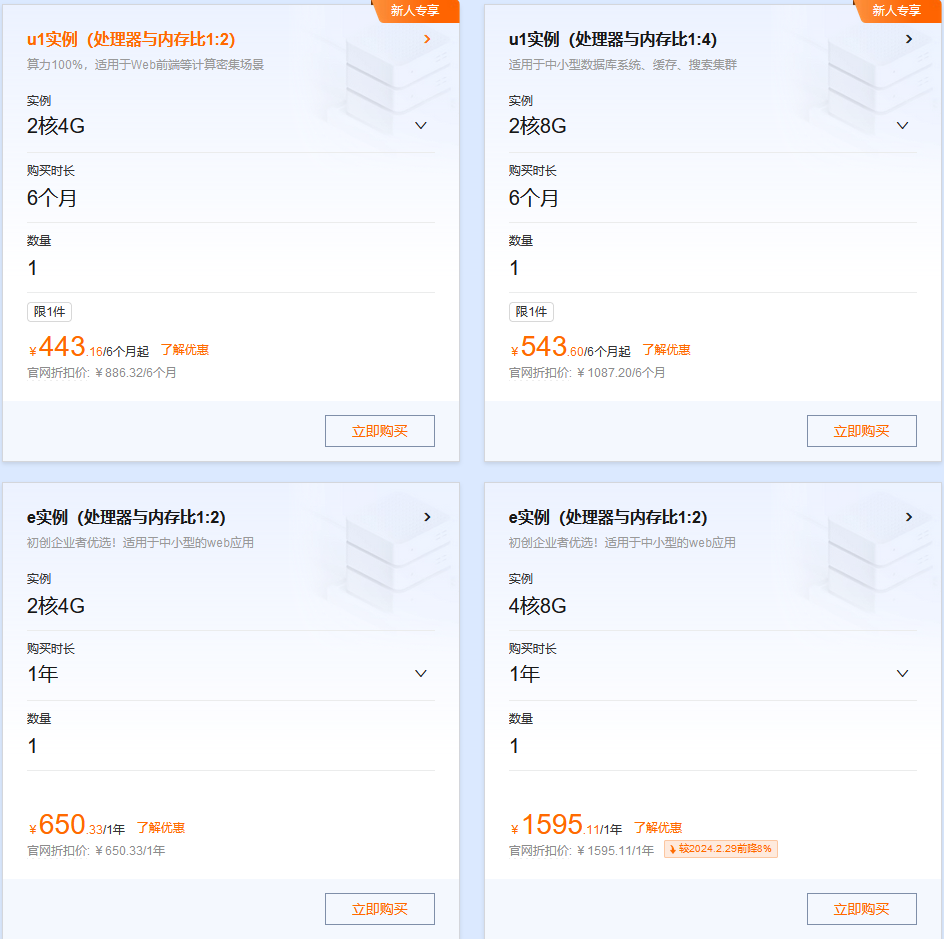
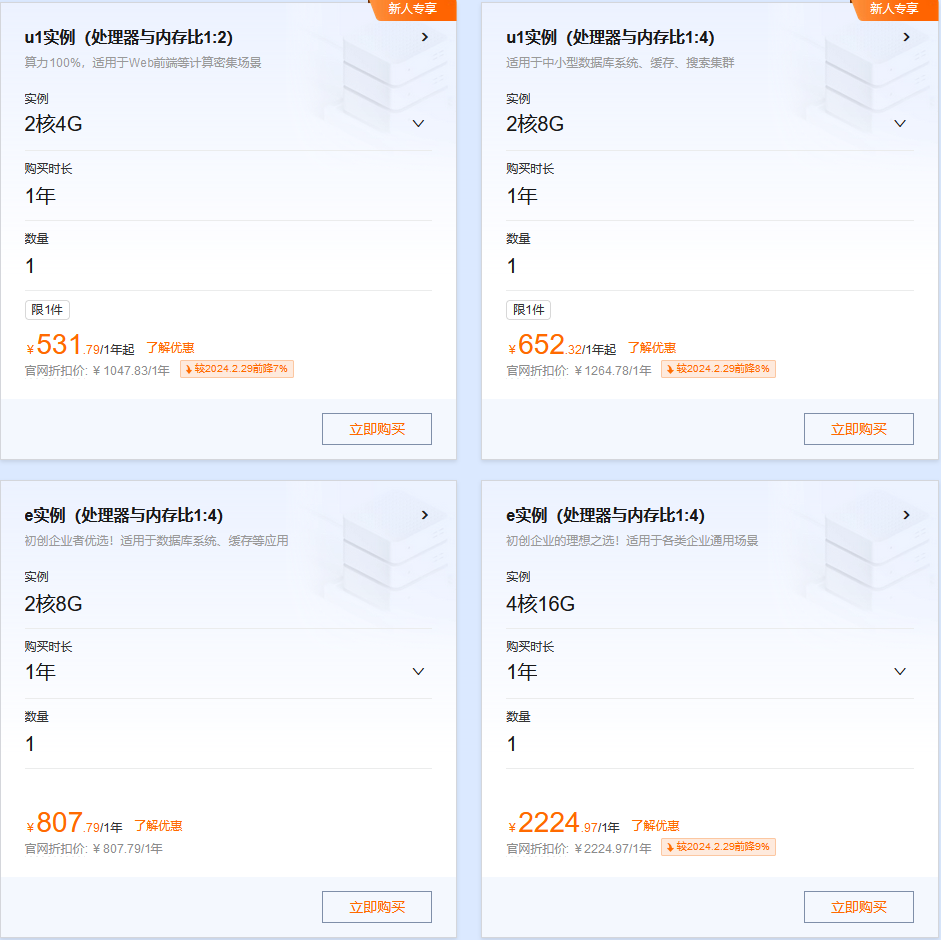
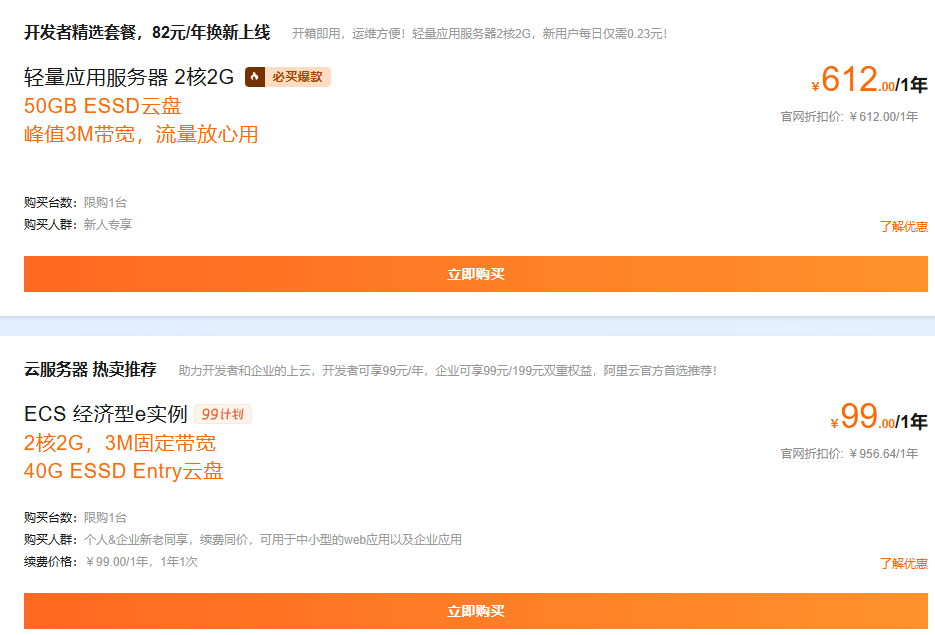
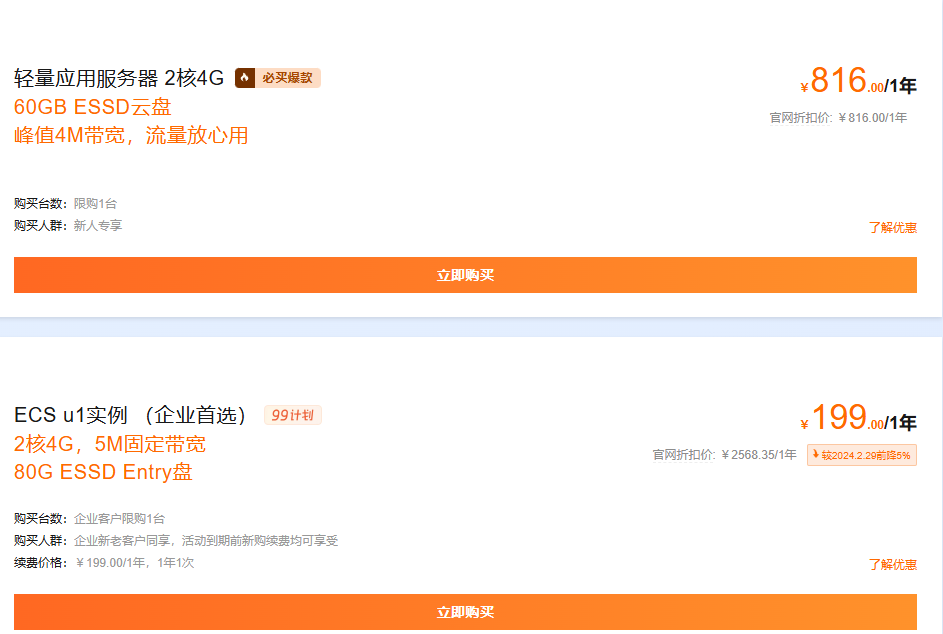
【腾讯云】2核2G云服务器新老同享 99元/年,续费同价,云服务器3年机/5年机限时抢购,低至 2.5折
2024-12-27
在Win10系统中如何设置打开自动搜索网络?本文将提供打开自动搜索网络的方法供大家了解。 打开自动搜索网络: 1、返回到win10系统的传统桌面位置,单击打开win10系统的开始菜单,然后从开始菜单中点击选择设置选项。 2、点击选择其中过的“网络和internet”选项,选择自己目前正在使用的网络 3、“查找设备和内容”开关,如果关闭则适用于“公共网络”,如果打开则适用于“家庭网络”和“工作网络”,在默认设置下Win10系统自动开启了“查找设备和内容”,如果看到这个选项是关闭的,那么就手动把它开启就可以了。 其实winXP系统和win7系统都有这样的功能,只是升级到win8系统或者win10系统之后,为了保护用户的电脑安全,Windows系统默认将这个功能禁止掉了,通过以上方法就可以打开了,有此需求的用户可以自己动手打开。 以上就是如何设置Win 10系统中的自动搜索网络的详细内容,更多请关注学派吧其它相关文章!
首先,来查看下系统当前都开放了什么端口,怎样查看呢?调出cmd命令行程序,输入命令”netstat -na“,可以看到。 接着,可以发现当前系统开放了135、445以及5357端口,而且从状态看都处于监听状态”Listening“。 然后,确认自己的系统已经开放了445端口之后,我们开始着手关闭这个高危端口。首先进入系统的”注册表编辑器“,步骤是:依次点击”开始“,”运行“,输入regedit进入”注册表编辑器“。 接着,依次点击注册表选项”HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\NetBT\Parameters“,进入NetBT这个服务的相关注册表项。 然后,在Parameters这个子项的右侧,点击鼠标右键,“新建”,“QWORD(64位)值”,然后重命名为“SMBDeviceEnabled”,再把这个子键的值改为0。 接着,如果你的系统为windows xp系统的话,那么重新启动就可以关闭系统的445端口了。但是如果是windows 7系统的话,这样还不行!你还要做的就是把操作系统的server服务关闭,依次点击“开始”,“运行”,输入services.msc,进入服务管理控制台。 然后,找到server服务,双击进入管理控制页面。把这个服务的启动类型更改为“禁用”,服务状态更改为“停止”,最后点击应用即可。 最后,重新启动操作系统看看吧,是不是445端口已经关闭了! 以上就是关于如何关闭window端口445的详细介绍的详细内容,更多请关注学派吧其它相关文章!
本篇文章给大家带来的内容是关于Navicat查看MySQL日志的方法教程(图),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 1、使用Navicat服务器监控工具 2、打开日志开关 右边参数设置变量"log"值为"ON" 3、定位日志位置,查看日志 4、执行SQL注入语句 5、查看日志记录 /* Style Definitions */ table.MsoNormalTable {mso-style-name:普通表格; mso-tstyle-rowband-size:0; mso-tstyle-colband-size:0; mso-style-noshow:yes; mso-style-priority:99; mso-style-parent:””; mso-padding-alt:0cm 5.4pt 0cm 5.4pt; mso-para-margin:0cm; mso-para-margin-bottom:.0001pt; mso-pagination:widow-orphan; font-size:10.5pt; mso-bidi-font-size:11.0pt; font-family:”Calibri”,”sans-serif”; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-bidi-font-family:”Times New Roman”; mso-bidi-theme-font:minor-bidi; mso-font-kerning:1.0pt;} 以上就是Navicat查看MySQL日志的方法步骤(图)的详细内容,更多请关注学派吧其它相关文章!
本篇文章给大家带来的内容是关于Navicat连接MySQL8.0的方法(有效),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 今天下了个 MySQL8.0,发现Navicat连接不上,总是报错1251; 原因是MySQL8.0版本的加密方式和MySQL5.0的不一样,连接会报错。 试了很多种方法,终于找到一种可以实现的: 更改加密方式 1.先通过命令行进入mysql的root账户: PS C:\Windows\system32> mysql -uroot -p 再输入root的密码: Enter password: ****** Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 18 Server version: 8.0.11 MySQL Community Server - GPL Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> 2.更改加密方式: mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'password' PASSWORD EXPIRE NEVER; Query OK, 0 rows affected (0.10 sec) 3.更改密码: mysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password'; Query OK, 0 rows affected...
本篇文章给大家带来的内容是关于navicat中对数据库操作的方法介绍,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 navicat我觉得做程序的基本上都会用,它方便,快捷,直观等,优点很多,这也是我写这篇文章的原因。以前我基本上都是用phpmyadmin,也挺好用,不过也有不少缺点,比如数据库备份文件太大,根本没法用导入,多数据库服务器管理,还要去配置phpmyadmin,其实挺不爽的。navicat对于刚用的人来说,其实也不是很方便,但是用熟就不一样了。下面就如何结合快捷键的方式,让navicat用着更舒服。 一,navicat如何写sql语句查询? 方法1:ctrl+q就会弹出一个sql输入窗口,就可以在里面写sql了。写完sql后,直接ctrl+r就执行sql了。还有一点,写sql语句时,navicat会提示的,根代码补全差不多,挺爽的。 方法2:按f6会弹出一个命令窗口,就根mysql -u mysql -p进去时操作一样,不过\G用的时候会报错。在这里也可以查询。 小技巧:这些窗口,可以拖动到一起的,看下图 navicat 多窗口切换 上图中有二个窗口,我们可以通过,快捷键ctrl+tab,在窗口间进行切换。 二,navicat如何备份,还原数据库,以及表? 方法1:右击数据名=》选中dump sql file就可以备份,如果要还原,就选execute sql file就行了。备份表,根备份数据库一样操作。还原表,就用import wizard就行了。这种备份导出来的只能是.sql文件。如果想备份成其他文件格式,看方法 2. 方法2:点击数据库,在点上方的export wizard就会弹出一个窗口,让你选择备份成什么样的文件,下一步 navicat 备份数据库,以及表 如果表太多,用这种方法备份,实在是不方便。如果是导入的话就用import wizard就行了。备份表同样的操作。 三,如何查看表数据和表结构? 双击表就可以查看表数据了,ctrl+d不光可以看到表结构,还可以看到索引,外键,触发器等。 四,如何管理多个mysql服务器? 点击左上方的connection按钮,多连接几个就行了。 五,如何用navicat对数据库管理员进行管理? 点击左上方manage users就会弹出一个窗口,里面会列出所有的mysql管理员。修改权限后,保存就行了。 以上就是navicat中对数据库操作的方法介绍的详细内容,更多请关注学派吧其它相关文章!
本篇文章给大家带来的内容是关于navicat如何为表添加索引?(图文),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 navicat 为表添加索引 分析常用的查询场景,为字段添加索引,增加查询速度。 可以添加单列索引,可以添加联合索引。 右键,设计表中可以查看和添加修改索引! 索引一定要根据常用的查询场景进行添加! 写了sql语句测试了一下,确实使用了索引! 可以通过名称来判断使用了什么索引! 帮与跟,让我感受到了索引的使用方法。 navicat软件还是很不错的! 我喜欢! 再谈优化查询,每一行代码,都能优化!每一个查询都能优化!写完接口之后,可以检查一下,哪里执行效率低了。数据少还看不出来,数据量一多。不好的设计就会展现的淋漓尽致! 以上就是navicat如何为表添加索引?(图文)的详细内容,更多请关注学派吧其它相关文章!
为了减少开发人员的错误操作,可以设置权限来进行控制,通过为MySQL服务器建立不同的用户,并为用户赋予不同的权限,来达到目标。这篇文章就给大家介绍怎么设置Navicat数据库的操作权限,需要的朋友可以参考一下。1 以下内容为详细设置步骤。 一、新建用户 1、用Navicat连接本地服务器(如果之前已连接,请打开连接) 2、点击菜单栏 –> 用户,如图所示: 3、点击新建用户,如下图所示: 用户名:设置连接服务器的用户名 主机:设置允许连接服务器的主机ip地址。%,代表此用户可以在所有主机上连接服务器;192.168.21.*,代表此用户只能在ip地址属于21段的主机上连接服务器;192.168.21.88,代表此用户只能在ip地址为192.168.21.88的主机上连接服务器。 密码:设置连接服务器的密码 确认密码:与密码设置保持一致 二、权限设置 如图上图所示,我们可以看到还有其他Tab项:高级、服务器权限、权限和SQL预览。 高级:可以设置此用户每小时最多查询数/最多更新数/最多连接数/最多用户连接数以及SSL。 服务器权限:设置对服务器上所有数据库的操作权限。 权限:设置具体的库和具体的表的权限。当与服务器权限设置冲突时,以服务器权限为准。 SQL预览:以上所有设置的SQL语句都会展示在这里。 服务器权限和权限选项卡的设置含义,请参考下面的权限说明。 三、权限说明 四、MySQL权限经验原则 权限控制主要是出于安全因素,因此需要遵循以下几个经验原则: 1、只授予能满足需要的最小权限,防止用户误操作或有意进行破坏操作。 2、创建用户时限制用户的登录主机,一般是限制成指定IP或者内网IP段。 3、初始化数据库的时候删除没有密码的用户。安装完数据库的时候回自动创建一些用户,这些用户默认没有密码。 4、为每个用户设置满足密码复杂度的密码。 5、定期清理不需要的用户。回收权限或者删除用户。 结语 学习一个新知识,看官方文档是最高效的方式。网上的其他学习资料大多经过加工,而且是往坏的方向加工。要不就是人云亦云,让人误入歧途。不过,很多时候还不得不从网上学习,因为大多数的官方文档是英文的,阅读起来真的是有困难。这个时候发现,能够轻松的阅读英文文档是非常珍贵的一项技能。 以上就是在Navicat中如何设置数据库的操作权限的详细内容,更多请关注学派吧其它相关文章!
本文章给大家带来的内容是关于巧用Navicat for MySQL的快捷键,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 巧妙地使用 Navicat for MySQL 快捷键,可以大大提高工作效率,本篇经验将分类介绍 Navicat for MySQL 快捷键。 ctrl+q 打开查询窗口 ctrl+/ 注释sql语句 ctrl+shift +/ 解除注释 ctrl+r 运行查询窗口的sql语句 ctrl+shift+r 只运行选中的sql语句 F6 打开一个mysql命令行窗口 ctrl+d (1):查看表结构详情,包括索引 触发器,存储过程,外键,唯一键;(2):复制一行 ctrl+l 删除一行 ctrl+n 打开一个新的查询窗口 ctrl+w 关闭一个查询窗口 ctrl+tab 多窗口切换 注意事项:请不要在一个窗口中写很多 update和delete! Navicat 主窗口,快捷键如下图所示: 表设计器,快捷键如下图所示: 表查看器,快捷键如下图所示: 视图查看器,快捷键如下图所示: 视图或查询,快捷键如下图所示: SQL 编辑器,快捷键如下图所示: 报表,快捷键如下图所示: 模型,快捷键如下图所示: 一,navicat如何写sql语句查询? 方法1:ctrl+q就会弹出一个sql输入窗口,就可以在里面写sql了。写完sql后,直接ctrl+r就执行sql了。还有一点,写sql语句时,navicat会提示的,根代码补全差不多,挺爽的。 方法2:按f6会弹出一个命令窗口,就根mysql -u mysql -p进去时操作一样,不过\G用的时候会报错。在这里也可以查询。 小技巧:这些窗口,可以拖动到一起的 navicat 多窗口切换,我们可以通过,快捷键ctrl+tab,在窗口间进行切换。 二,navicat如何备份,还原数据库,以及表? 方法1:右击数据名=》选中dump sql file就可以备份,如果要还原,就选execute sql file就行了。备份表,根备份数据库一样操作。还原表,就用import wizard就行了。这种备份导出来的只能是.sql文件。如果想备份成其他文件格式,看方法 2. 方法2:点击数据库,在点上方的export wizard就会弹出一个窗口,让你选择备份成什么样的文件,下一步 navicat 备份数据库,以及表 如果表太多,用这种方法备份,实在是不方便。如果是导入的话就用import wizard就行了。备份表同样的操作。 三,如何查看表数据和表结构? 双击表就可以查看表数据了,ctrl+d不光可以看到表结构,还可以看到索引,外键,触发器等。 四,如何管理多个mysql服务器? 点击左上方的connection按钮,多连接几个就行了。 五,如何用navicat对数据库管理员进行管理? 点击左上方manage users就会弹出一个窗口,里面会列出所有的mysql管理员。修改权限后,保存就行了。 上面5点,只是一些常用的,基本的操作,navicat还有很多人性化的操作。在这里就不多说了,有兴趣的朋友,可以下一个来玩玩。个人觉得用着挺爽的。 以上就是巧用Navicat for MySQL的快捷键的详细内容,更多请关注学派吧其它相关文章!
本篇文章主要介绍了navicat for mysql下载安装以及简单的使用,有对novicat for mysql 感兴趣的小伙伴可以参考一下 一:下载Navicat for MySQL 下载地址:http://www.php.cn/xiazai/gongju/757 二:安装Navicat for MySQL 运行 → 下一步 → 点击“我同意” → 选择安装路径 → 保留默认,下一步 → 选择是否创建桌面图标,建议保留默认值,点击“下一步” → 安装 → 完成。 三:破解Navicat for MySQL 下载完成后解压出PatchNavicat.exe文件复制到Navicat for MySQL目录下,双击PatchNavicat.exe运行(必须在关闭Navicat for MySQL的情况下),选择启动文件navicat.exe,提示Path Successfully!说明破解成功。现在打开navicat.exe,可能依旧提醒需要注册不过不用管,重新启动即可。 四、 简单的使用 连接数据库。(Navicat可以连接大部分最常用的的数据库,以下以mysql为例) 2.点击Mysql,进入连接数据库界面,此处“连接名”可以随意写,最好与你的项目相关,主机名和IP地址就填你想要连接数据库所在地址,端口的话,mysql默认的是3306端口,用户名和密码就是你数据库的用户名和密码。 3、点击“连接测试”可以测试是否能够连接数据库,成功连接之后点击确定就行。成功连接后进入下图界面。双击数据库下的库名可以打开相应的数据库 4、右键表,可以选择添加数据库表,此处需要记住的是,栏位就代表数据库的字段,添加栏位就是添加字段,可以对字段的名字、类型等进行定义。定义好字段之后点击保存输入表名即可。 5、建立库表之后就可以往表里插入数据了。数据插好之后,点击下方的分别表示“添加数据,删除数据,保存,撤销,刷新”等操作。 相关推荐: navicat for mysql 注册码 和 mysql数据库管理工具 Navicat for MySQL定时备份数据库及数据恢复操作 如何利用Navicat for MySQL数据库进行数据传输 MySQL数据库如何利用用navicat新建用户? 以上就是 navicat for mysql下载安装以及简单的使用的详细内容,更多请关注学派吧其它相关文章!
本篇文章给大家带来的内容是关于Redis与Memcached有何区别 ?redis和Memcached的区别比较,有一定的参考价值,有需要的朋友可以参考一下, memcached和redis,作为近些年最常用的缓存服务器,相信大家对它们再熟悉不过了。前两年还在学校时,我曾经读过它们的主要源码,如今写篇笔记从个人角度简单对比一下它们的实现方式,权当做复习,有理解错误之处,欢迎指正。 文中使用的架构类的图片大多来自于网络,有部分图与最新实现有出入,文中已经指出。 一. 综述 读一个软件的源码,首先要弄懂软件是用作干什么的,那memcached和redis是干啥的?众所周知,数据一般会放在数据库中,但是查询数据会相对比较慢,特别是用户很多时,频繁的查询,需要耗费大量的时间。怎么办呢?数据放在哪里查询快?那肯定是内存中。memcached和redis就是将数据存储在内存中,按照key-value的方式查询,可以大幅度提高效率。所以一般它们都用做缓存服务器,缓存常用的数据,需要查询的时候,直接从它们那儿获取,减少查询数据库的次数,提高查询效率。 二. 服务方式 memcached和redis怎么提供服务呢?它们是独立的进程,需要的话,还可以让他们变成daemon进程,所以我们的用户进程要使用memcached和redis的服务的话,就需要进程间通信了。考虑到用户进程和memcached和redis不一定在同一台机器上,所以还需要支持网络间通信。因此,memcached和redis自己本身就是网络服务器,用户进程通过与他们通过网络来传输数据,显然最简单和最常用的就是使用tcp连接了。另外,memcached和redis都支持udp协议。而且当用户进程和memcached和redis在同一机器时,还可以使用unix域套接字通信。 三. 事件模型 下面开始讲他们具体是怎么实现的了。首先来看一下它们的事件模型。 自从epoll出来以后,几乎所有的网络服务器全都抛弃select和poll,换成了epoll。redis也一样,只不多它还提供对select和poll的支持,可以自己配置使用哪一个,但是一般都是用epoll。另外针对BSD,还支持使用kqueue。而memcached是基于libevent的,不过libevent底层也是使用epoll的,所以可以认为它们都是使用epoll。epoll的特性这里就不介绍了,网上介绍文章很多。 它们都使用epoll来做事件循环,不过redis是单线程的服务器(redis也是多线程的,只不过除了主线程以外,其他线程没有event loop,只是会进行一些后台存储工作),而memcached是多线程的。 redis的事件模型很简单,只有一个event loop,是简单的reactor实现。不过redis事件模型中有一个亮点,我们知道epoll是针对fd的,它返回的就绪事件也是只有fd,redis里面的fd就是服务器与客户端连接的socket的fd,但是处理的时候,需要根据这个fd找到具体的客户端的信息,怎么找呢?通常的处理方式就是用红黑树将fd与客户端信息保存起来,通过fd查找,效率是lgn。不过redis比较特殊,redis的客户端的数量上限可以设置,即可以知道同一时刻,redis所打开的fd的上限,而我们知道,进程的fd在同一时刻是不会重复的(fd只有关闭后才能复用),所以redis使用一个数组,将fd作为数组的下标,数组的元素就是客户端的信息,这样,直接通过fd就能定位客户端信息,查找效率是O(1),还省去了复杂的红黑树的实现(我曾经用c写一个网络服务器,就因为要保持fd和connect对应关系,不想自己写红黑树,然后用了STL里面的set,导致项目变成了c++的,最后项目使用g++编译,这事我不说谁知道?)。显然这种方式只能针对connection数量上限已确定,并且不是太大的网络服务器,像nginx这种http服务器就不适用,nginx就是自己写了红黑树。 而memcached是多线程的,使用master-worker的方式,主线程监听端口,建立连接,然后顺序分配给各个工作线程。每一个从线程都有一个event loop,它们服务不同的客户端。master线程和worker线程之间使用管道通信,每一个工作线程都会创建一个管道,然后保存写端和读端,并且将读端加入event loop,监听可读事件。同时,每个从线程都有一个就绪连接队列,主线程连接连接后,将连接的item放入这个队列,然后往该线程的管道的写端写入一个connect命令,这样event loop中加入的管道读端就会就绪,从线程读取命令,解析命令发现是有连接,然后就会去自己的就绪队列中获取连接,并进行处理。多线程的优势就是可以充分发挥多核的优势,不过编写程序麻烦一点,memcached里面就有各种锁和条件变量来进行线程同步。 四. 内存分配 memcached和redis的核心任务都是在内存中操作数据,内存管理自然是核心的内容。 首先看看他们的内存分配方式。memcached是有自己得内存池的,即预先分配一大块内存,然后接下来分配内存就从内存池中分配,这样可以减少内存分配的次数,提高效率,这也是大部分网络服务器的实现方式,只不过各个内存池的管理方式根据具体情况而不同。而redis没有自己得内存池,而是直接使用时分配,即什么时候需要什么时候分配,内存管理的事交给内核,自己只负责取和释放(redis既是单线程,又没有自己的内存池,是不是感觉实现的太简单了?那是因为它的重点都放在数据库模块了)。不过redis支持使用tcmalloc来替换glibc的malloc,前者是google的产品,比glibc的malloc快。 由于redis没有自己的内存池,所以内存申请和释放的管理就简单很多,直接malloc和free即可,十分方便。而memcached是支持内存池的,所以内存申请是从内存池中获取,而free也是还给内存池,所以需要很多额外的管理操作,实现起来麻烦很多,具体的会在后面memcached的slab机制讲解中分析。 五. 数据库实现 接下来看看他们的最核心内容,各自数据库的实现。 1. memcached数据库实现 memcached只支持key-value,即只能一个key对于一个value。它的数据在内存中也是这样以key-value对的方式存储,它使用slab机制。 首先看memcached是如何存储数据的,即存储key-value对。如下图,每一个key-value对都存储在一个item结构中,包含了相关的属性和key和value的值。 item是保存key-value对的,当item多的时候,怎么查找特定的item是个问题。所以memcached维护了一个hash表,它用于快速查找item。hash表适用开链法(与redis一样)解决键的冲突,每一个hash表的桶里面存储了一个链表,链表节点就是item的指针,如上图中的h_next就是指桶里面的链表的下一个节点。 hash表支持扩容(item的数量是桶的数量的1.5以上时扩容),有一个primary_hashtable,还有一个old_hashtable,其中正常适用primary_hashtable,但是扩容的时候,将old_hashtable = primary_hashtable,然后primary_hashtable设置为新申请的hash表(桶的数量乘以2),然后依次将old_hashtable 里面的数据往新的hash表里面移动,并用一个变量expand_bucket记录以及移动了多少个桶,移动完成后,再free原来的old_hashtable 即可(redis也是有两个hash表,也是移动,不过不是后台线程完成,而是每次移动一个桶)。扩容的操作,专门有一个后台扩容的线程来完成,需要扩容的时候,使用条件变量通知它,完成扩容后,它又考试阻塞等待扩容的条件变量。这样在扩容的时候,查找一个item可能会在primary_hashtable和old_hashtable的任意一个中,需要根据比较它的桶的位置和expand_bucket的大小来比较确定它在哪个表里。 item是从哪里分配的呢?从slab中。如下图,memcached有很多slabclass,它们管理slab,每一个slab其实是trunk的集合,真正的item是在trunk中分配的,一个trunk分配一个item。一个slab中的trunk的大小一样,不同的slab,trunk的大小按比例递增,需要新申请一个item的时候,根据它的大小来选择trunk,规则是比它大的最小的那个trunk。这样,不同大小的item就分配在不同的slab中,归不同的slabclass管理。 这样的缺点是会有部分内存浪费,因为一个trunk可能比item大,如图2,分配100B的item的时候,选择112的trunk,但是会有12B的浪费,这部分内存资源没有使用。 如上图,整个构造就是这样,slabclass管理slab,一个slabclass有一个slab_list,可以管理多个slab,同一个slabclass中的slab的trunk大小都一样。slabclass有一个指针slot,保存了未分配的item已经被free掉的item(不是真的free内存,只是不用了而已),有item不用的时候,就放入slot的头部,这样每次需要在当前slab中分配item的时候,直接取slot取即可,不用管item是未分配过的还是被释放掉的。 然后,每一个slabclass对应一个链表,有head数组和tail数组,它们分别保存了链表的头节点和尾节点。链表中的节点就是改slabclass所分配的item,新分配的放在头部,链表越往后的item,表示它已经很久没有被使用了。当slabclass的内存不足,需要删除一些过期item的时候,就可以从链表的尾部开始删除,没错,这个链表就是为了实现LRU。光靠它还不行,因为链表的查询是O(n)的,所以定位item的时候,使用hash表,这已经有了,所有分配的item已经在hash表中了,所以,hash用于查找item,然后链表有用存储item的最近使用顺序,这也是lru的标准实现方法。 每次需要新分配item的时候,找到slabclass对于的链表,从尾部往前找,看item是否已经过期,过期的话,直接就用这个过期的item当做新的item。没有过期的,则需要从slab中分配trunk,如果slab用完了,则需要往slabclass中添加slab了。 memcached支持设置过期时间,即expire time,但是内部并不定期检查数据是否过期,而是客户进程使用该数据的时候,memcached会检查expire time,如果过期,直接返回错误。这样的优点是,不需要额外的cpu来进行expire time的检查,缺点是有可能过期数据很久不被使用,则一直没有被释放,占用内存。 memcached是多线程的,而且只维护了一个数据库,所以可能有多个客户进程操作同一个数据,这就有可能产生问题。比如,A已经把数据更改了,然后B也更改了改数据,那么A的操作就被覆盖了,而可能A不知道,A任务数据现在的状态时他改完后的那个值,这样就可能产生问题。为了解决这个问题,memcached使用了CAS协议,简单说就是item保存一个64位的unsigned int值,标记数据的版本,每更新一次(数据值有修改),版本号增加,然后每次对数据进行更改操作,需要比对客户进程传来的版本号和服务器这边item的版本号是否一致,一致则可进行更改操作,否则提示脏数据。 以上就是memcached如何实现一个key-value的数据库的介绍。 2. redis数据库实现 首先redis数据库的功能强大一些,因为不像memcached只支持保存字符串,redis支持string, list, set,sorted set,hash table 5种数据结构。例如存储一个人的信息就可以使用hash table,用人的名字做key,然后name super, age 24, 通过key 和 name,就可以取到名字super,或者通过key和age,就可以取到年龄24。这样,当只需要取得age的时候,不需要把人的整个信息取回来,然后从里面找age,直接获取age即可,高效方便。 为了实现这些数据结构,redis定义了抽象的对象redis object,如下图。每一个对象有类型,一共5种:字符串,链表,集合,有序集合,哈希表。 同时,为了提高效率,redis为每种类型准备了多种实现方式,根据特定的场景来选择合适的实现方式,encoding就是表示对象的实现方式的。然后还有记录了对象的lru,即上次被访问的时间,同时在redis 服务器中会记录一个当前的时间(近似值,因为这个时间只是每隔一定时间,服务器进行自动维护的时候才更新),它们两个只差就可以计算出对象多久没有被访问了。 然后redis object中还有引用计数,这是为了共享对象,然后确定对象的删除时间用的。最后使用一个void*指针来指向对象的真正内容。正式由于使用了抽象redis object,使得数据库操作数据时方便很多,全部统一使用redis object对象即可,需要区分对象类型的时候,再根据type来判断。而且正式由于采用了这种面向对象的方法,让redis的代码看起来很像c++代码,其实全是用c写的。 //#define REDIS_STRING 0 // 字符串类型 //#define REDIS_LIST 1 // 链表类型 //#define REDIS_SET 2 // 集合类型(无序的),可以求差集,并集等 //#define REDIS_ZSET 3 // 有序的集合类型 //#define REDIS_HASH 4 // 哈希类型 //#define REDIS_ENCODING_RAW 0 /* Raw representation */ //raw 未加工 //#define REDIS_ENCODING_INT 1 /* Encoded as integer */ //#define REDIS_ENCODING_HT 2...
本篇文章给大家带来的内容是关于CPU资源和可用内存大小对数据库性能有何影响?有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助 前言 可能影响到数据库性能的几个点,其一就是服务器硬件,也是本节要说的CPU与可用内存。 引入 当热数据超过可用内存大小,MemCache存储引擎缓存层容易失效(当缓存大量失效时,容易产生大量的网络传输),从而影响服务器的性能。 当出现这类I/O系统瓶颈时,我们就需要升级I/O子系统,来增加更多的内存,网络与I/O资源就是对我们数据库性能影响的第二个硬件因素。 CPU选型 采购人员经常性会向我们请教需要买什么参数的CPU硬件等等。 我到时想什么都买最好的!可是成本这种东西,只能让你选其一 那么,我们的CPU是要频率还是数量呢? 首先我们应该知道我们的应用是否是CPU密集型? 其实大多数时候我们要选择更好的而不是更多的 对于目前版本的MYSQL,不支持多CPU对同一SQL并发处理 当然,我们也要看看系统的并发量如何?(并发是纳秒级别的) 衡量数据库处理能力的指标 QPS:同时处理SQL的数量(这里是每秒) MYSQL目前被大量应用于Web类的应用中,这类应用的并发量也是非常大的,则其CPU核心数量就比频率重要 同时也要考虑所使用的MYSQL的版本(高版本对多核CPU的支持较好、起码你可以放心使用16核或者32核的CPU) 当然,如果你想要使用多核CPU的话,还需要使用MYSQL最新版本,这样才能做到最好的性能。 关于内存 MYSQL本身是单线程的 内存的大小直接影响MYSQL的性能 把数据存储到缓存中,可以大大提高数据的性能 常用的MYSQL存储引擎 MyISAM 将索引存储到内存中,数据则放在操作系统中 InnoDB 则是同时在内存存储索引和数据,进而提高数据库运行效率 内存配置的提示 1、内存虽然越多越好,但是对性能的影响是有限的,并不能无限的增加性能 2、当然,多余的内存,可以增加操作系统等其他服务的性能 缓存对读有益处,同时对写操作也有益处 CPU -》 内存 -》 磁盘 缓存可以对写操作进行延缓,将多次写入变成一次写入(Eg:浏览量计数器 以上就是CPU资源和可用内存大小对数据库性能有何影响?的详细内容,更多请关注学派吧其它相关文章!
本篇文章给大家带来的内容是mysql数据库中影响性能因素的讲解(附数据库架构案例),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 关于数据库性能的故事 面试时多多少少会讲到数据库上的事情,“你对数据库的掌握如何?”,什么时候最考验数据库的性能,答应主要方面上讲就是大数据量的读写时,而电商类的大促活动就是考验各自的数据库性能的时候啦。 对于web服务器而言,数据量大时,我们可以简单的通过横向扩展来减少单个服务器的负担,但是对于数据库服务器来说就没有那么简单了,他们不可能做到轻易的横向扩展,这样也违背了数据库的完整性与一致性的原则,那么我们的数据库架构该如何搭建呢? 对于大促类活动而言,不管是产品多好、策划多成功,如果没有稳定的数据库及服务器环境,则这所谓的一切都将是一场空呀。 数据库架构案例 如图所示,主从服务器之间没有任何主从复制组件,即当主服务器出现了故障,很难进行主服务器的切换,这需要DBA在从服务器中选择数据最新的从服务器将其提升为主服务器并同步其他从服务器,这个过程的时间成本也是非常沉重的。 且过多的从服务器,当业务量大时对主服务器的网卡也是一定的挑战。 我们可以通过对集群的监控信息来了解是什么影响了数据库性能。 答应其实是肯定的,一般情况下主要是QPS与TPS、并发量(同一时间处理的请求的数量,避免和同时连接数混淆)、磁盘IO、读操作过于高 这里有个建议:最好不要在主库上数据备份,起码在大型活动前要取消这类计划、 影响数据库的因素 sql查询速度 服务器硬件 网卡流量 磁盘IO 超高的QPS和TPS 风险:效率底下的SQL(QPS:每秒钟处理的查询量) 大量的并发和超高的CPU使用率 风险:大量的并发(数据库连接数被占满(max_connections默认100)) 风险:超高的CPU使用率(因CPU资源耗尽而出现宕机) 磁盘IO 风险:磁盘IO性能突然下降(使用更快的磁盘设备) 风险:其他大量消耗磁盘性能的计划任务(调整计划任务) 网卡流量 风险:网卡IO被占满(1000Mb/8=100MB) 如何避免无法连接数据库的情况: 1、减少从服务器的数量 2、进行分级缓存 3、避免使用“select * ”进行查询 4、分离业务网络和服务器网络 以上就是mysql数据库中影响性能因素的讲解(附数据库架构案例)的详细内容,更多请关注学派吧其它相关文章!
本篇文章给大家带来的内容是关于python中进程池的简单实现代码,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助 1. 在所有用于where,order by和group by的列上添加索引 索引除了能够确保唯一的标记一条记录,还能是MySQL服务器更快的从数据库中获取结果。索引在排序中的作用也非常大。 Mysql的索引可能会占据额外的空间,并且会一定程度上降低插入,删除和更新的性能。但是,如果你的表格有超过10行数据,那么索引就能极大的降低查找的执行时间。 强烈建议使用“最坏情况的数据样本”来测试MySql查询,从而更清晰的了解查询在生产中的行为方式。 假设你正在一个超过500行的数据库表中执行如下的查询语句: mysql>select customer_id, customer_name from customers where customer_id='345546' 上述查询会迫使Mysql服务器执行一个全表扫描来获得所查找的数据。 型号,Mysql提供了一个特别的Explain语句,用来分析你的查询语句的性能。当你将查询语句添加到该关键词后面时,MySql会显示优化器对该语句的所有信息。 如果我们用explain语句分析一下上面的查询,会得到如下的分析结果: mysql> explain select customer_id, customer_name from customers where customer_id='140385'; +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | customers | NULL | ALL | NULL | NULL | NULL | NULL | 500 | 10.00 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 可以看到,优化器展示出了非常重要的信息,这些信息可以帮助我们微调数据库表。首先,MySql会执行一个全表扫描,因为key列为Null。其次,MySql服务器已经明确表示它将要扫描500行的数据来完成这次查询。 为了优化上述查询,我们只需要在customer_id这一列上添加一个索引m即可: mysql> Create index customer_id ON customers (customer_Id); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 如果我们再次执行explain语句,会得到如下结果: mysql> Explain select customer_id, customer_name from customers where customer_id='140385'; +----+-------------+-----------+------------+------+---------------+-------------+---------+-------+------+----------+-------+ | id | select_type |...
本篇文章给大家带来的内容是关于Redis是什么?有哪些应用场景?有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 一丶Redis介绍 1 Redis是一个开源的 key—value型 单线程 数据库,支持string、list、set、zset和hash类型数据。 默认端口:6379 默认数据库数量:16 二、优点: 1.nosql数据库没有关联关系,数据结构简单,拓展表比较容易 2.nosql读取速度快,对较大数据处理快 三、适用场景: 1.数据高并发的读写 2.海量数据的读写 对扩展性要求高的数据 四、不适场景: 1.需要事务支持(非关系型数据库) 2.基于sql结构化查询储存,关系复杂 五、应用场景 下面这些作者是Redis作者@antirez,他描述了Redis比较适合的一些应用场景,NoSQLFan简单列举在这里,供大家一览: 1.取最新N个数据的操作 比如典型的取你网站的最新文章,通过下面方式,我们可以将最新的5000条评论的ID放在Redis的List集合中,并将超出集合部分从数据库获取 使用LPUSH latest.comments<ID>命令,向list集合中插入数据 插入完成后再用LTRIM latest.comments 0 5000命令使其永远只保存最近5000个ID 然后我们在客户端获取某一页评论时可以用下面的逻辑(伪代码) FUNCTION get_latest_comments(start,num_items): id_list = redis.lrange("latest.comments",start,start+num_items-1) IF id_list.length < num_items id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...") END RETURN id_list END 如果你还有不同的筛选维度,比如某个分类的最新N条,那么你可以再建一个按此分类的List,只存ID的话,Redis是非常高效的。 2.排行榜应用,取TOP N操作 这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。 3.需要精准设定过期时间的应用 比如你可以把上面说到的sorted set的score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把Redis里这个过期时间当成是对数据库中数据的索引,用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。 4.计数器应用 Redis的命令都是原子性的,你可以轻松地利用INCR,DECR命令来构建计数器系统。 5.Uniq操作,获取某段时间所有数据排重值 这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。 6.实时系统,反垃圾系统 通过上面说到的set功能,你可以知道一个终端用户是否进行了某个操作,可以找到其操作的集合并进行分析统计对比等。没有做不到,只有想不到。 7.Pub/Sub构建实时消息系统 Redis的Pub/Sub系统可以构建实时的消息系统,比如很多用Pub/Sub构建的实时聊天系统的例子。 8.构建队列系统 使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。 以上就是Redis是什么?有哪些应用场景?的详细内容,更多请关注学派吧其它相关文章!
本篇文章给大家带来的内容是关于Redis的事务操作的命令与执行操作(代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 序1 本文主要研究一下redis的事务操作 命令 multi与exec 命令行 127.0.0.1:6379> multi OK 127.0.0.1:6379> incr total QUEUED 127.0.0.1:6379> incr len QUEUED 127.0.0.1:6379> exec 1) (integer) 2 2) (integer) 2 127.0.0.1:6379> get total "2" 127.0.0.1:6379> get len "2" lettuce实例 @Test public void testMultiExec(){ RedisClient client = RedisClient.create("redis://192.168.99.100:6379/0"); StatefulRedisConnection<String, String> connection = client.connect(); RedisCommands<String, String> syncCommands = connection.sync(); syncCommands.set("hello","1"); syncCommands.set("world","2"); syncCommands.multi(); syncCommands.incr("hello"); syncCommands.incr("world"); //DefaultTransactionResult[wasRolledBack=false,result=[1, 2, 1, 3, 1]] TransactionResult transactionResult = syncCommands.exec(); System.out.println(transactionResult); System.out.println(syncCommands.get("hello")); System.out.println(syncCommands.get("world")); } 部分执行 命令行 127.0.0.1:6379> multi OK 127.0.0.1:6379> set a hello QUEUED 127.0.0.1:6379> set b world QUEUED 127.0.0.1:6379> incr a QUEUED 127.0.0.1:6379> set c part QUEUED 127.0.0.1:6379> exec 1) OK 2) OK 3) (error) ERR value is not an integer or out of range 4) OK 127.0.0.1:6379> get a "hello" 127.0.0.1:6379> get...
本篇文章给大家带来的内容是关于如何快速简单的优化快照使用成本,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。 如何优化快照使用成本 快照推荐使用场景 快照作为一种便捷高效的数据保护服务手段,推荐应用于以下业务场景中: 系统盘、数据盘的日常备份。您可以利用快照定期的对重要业务数据进行备份,来应对误操作、攻击、病毒等导致的数据丢失风险。 更换操作系统。应用软件升级或业务数据迁移等重大操作前,您可以创建一份或多份数据快照,一旦升级、迁移过程中出现任何问题,可以通过数据快照及时恢复到正常的系统数据状态。 生产数据的多副本应用。您可以通过对生产数据创建快照,从而为数据挖掘、报表查询、开发测试等应用提供近实时的真实生产数据。 保留合理的快照数量 快照是按照所占用的存储容量来计算收费,因此保留快照数量越多,所占用的存储容量会越大,那么产生的快照费用也会随之增加。因此,为了减少不必要的快照使用成本,建议您根据实际业务需求,合理设置快照策略,保留合适数量的快照。 业务场景和建议见下表。 这样,既可以实现数据的定期备份,也不会产生过于昂贵的费用。同时,快照支持预付费存储包和按量后付费模式,方便您选择适合自己的消费模式。 如何删除创建了镜像、磁盘的快照 快照,镜像,磁盘,实例当前是绑定的关系,重置系统盘初始化磁盘功能都会依赖于以上相互之间的绑定关系。在2017年4月份我们已经解耦了“镜像与实例”、“快照与磁盘”之间的绑定关系。 创建过实例的镜像,可以单独删除,但删除后,类似依赖于原始镜像数据的业务操作,比如重新初始化磁盘操作就无法操作了; 创建过磁盘的快照,可以单独删除,同样删除后,依赖于原始快照数据状态的业务操作,比如重新初始化磁盘操作就无法操作了; 创建了镜像的快照,在删除之前,需要先删除所对应的镜像,才能删除。 以上就是如何快速简单的优化快照使用成本的详细内容,更多请关注学派吧其它相关文章