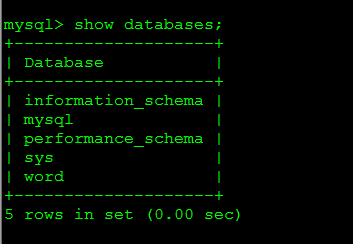
centos(linux)下如何备份数据库教程说明-已经测试过
有些公司的网站负责人朋友刚接触到公司业务。对linux 还不是很熟悉 对网站的数据库无法进行备份。 今天给大家分享下 、 1.MySQL的登录命令 登录Mysql输入:mysql -u帐号 -p密码 注:密码可以之后输入 案例: mysq...
有些公司的网站负责人朋友刚接触到公司业务。对linux 还不是很熟悉 对网站的数据库无法进行备份。 今天给大家分享下 、 1.MySQL的登录命令 登录Mysql输入:mysql -u帐号 -p密码 注:密码可以之后输入 案例: mysq...

前沿 今天通过ECS对阿里云rds数据库进行导入。一直报错。 mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 12...

【腾讯云】3年轻量2核2G4M 低至1.7折,仅需368元!
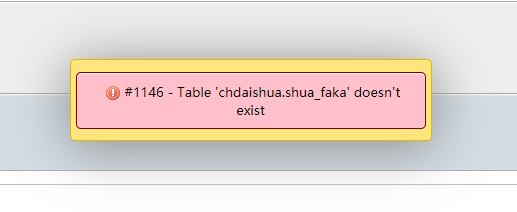
今天看到一个案例:数据库服务无法启动,也导致了不能备份数据库、所以只能使用了笨方法、直接打包DATA目录 我们的服务器是宝塔环境、 直接备份 /www/server/data 这个目录备份 下载下来 在新的服务器上安装好环境、把data...
本文主要讲述了在在linux系统下启动 mysql数据库操作,感兴趣的朋友可以了解一下。 {mysql}表示mysql的安装目录 如何启动/停止/重启MySQL 一、启动方式 1、使用 service 启动:service mysqld s...

本篇文章的主要内容是关于在mysql数据库explain中的using where和using index的使用,感兴趣的朋友可以了解一下。 1. 查看表中的所有索引 show index from modify_passwd_log; 有...
数据库中schema是数据库对象集合,它包含了表,视图等多种对象。schema就像是用户名,当访问数据表时未指明属于哪个schema,系统就会自动的加上缺省的schema 我们在学习数据库中会碰到一个模糊的概念,它就是Schema。很多人对...
最近对php查询mysql处理结果集的几个方法不太明白的地方查阅了资料,在此整理记下(相关推荐:mysql教程) Php使用mysqli_result类处理结果集有以下几种方法 fetch_all() 抓取所有的结果行并且以关联数据,数值索...
本文的主要内容是讲述在MySQL 5.7上使用group by语句出现1055错误的问题分析以及解决办法,有需要的朋友可以看一下。 1. 在5.7版本以上mysql中使用group by语句进行分组时, 如果select的字段 , 不是完全...
mysql数据库事务的隔离级别有4个,而默认的事务处理级别就是’REPEATABLE-READ’,也就是可重复读。下面本篇文章就来带大家了解一下mysql的这4种事务的隔离级别,希望对大家有所帮助。 SQL标准定义了...
为查询优化你的查询 大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接...
MySQL有多种存储引擎,MyISAM和InnoDB是其中常用的两种。这里介绍关于这两种引擎的一些基本概念(非深入介绍)。 MyISAM是MySQL的默认存储引擎,基于传统的ISAM类型,支持全文搜索,但不是事务安全的,而且不支持外键。每张...
接上一节《百万数据mysql分页问题》,我们加上查询条件: select id from news where cate = 1 order by id desc limit 500000 ,10 查询时间 20 秒 好恐怖的速度!!利用第...
Apache服务器是一个开源跨平台的web服务器。它具有多种免费且开源的web技术,适应多种操作系统。另外它还具有为软件添加更多功能的模块,使得它成为功能最丰富的HTTP网络服务器 Apache是一种流行的开源,跨平台的Web服务器,同时它...
在开发过程中我们经常会使用分页,核心技术是使用limit进行数据的读取。在使用limit进行分页的测试过程中,得到以下数据: select * from news order by id desc limit 0,10 耗时0.003秒 s...
information_schema提供了对数据库元数据、统计信息、以及有关MySQL Server的信息访问(例如:数据库名或表名,字段的数据类型和访问权限等)。information_schema库中保存的信息也可以称为MySQL的数据...
在MySQL中,RLIKE运算符用于确定字符串是否匹配正则表达式。它是REGEXP_LIKE()的同义词。 如果字符串与提供的正则表达式匹配,则结果为1,否则为0。 语法是这样的: expr RLIKE pat 其中expr是输入字符串,p...
本文主要讲述了当mysql禁止外部访问的解决方案,具有一定的收藏价值,有需要的朋友了解一下吧。 1.在端口已经开放的情况下,ubuntu mysql 3306允许远程访问vim /etc/mysql/mysql.conf.d/mysqld....

今天主要写mysql在centos下 通过命令导出 导入教程分享 服务器:商祺云服务器 – https://www.sq9.cn 开始: 备份: mysqldump -u数据库名 -p"密码" -h localhost 数...




每天两场(上午10:00,下午15:00),上云首选云服务器限量抢购,助力低成本上云
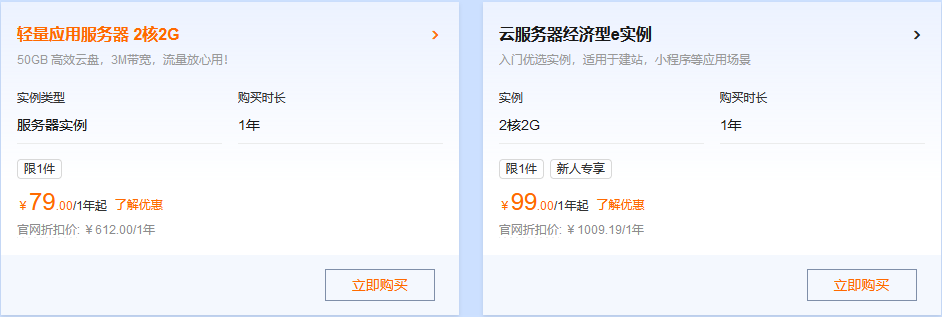
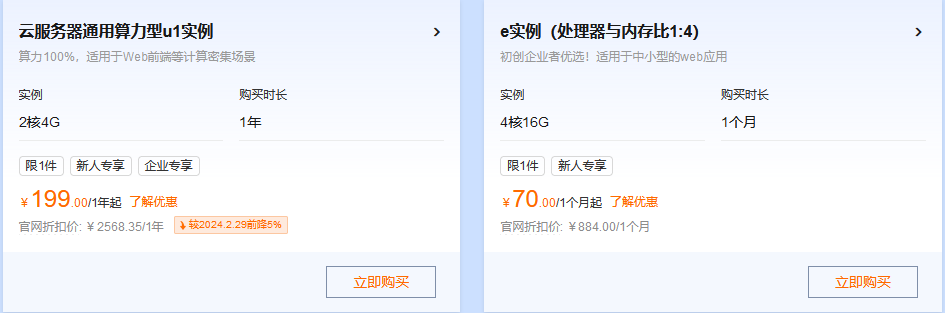
阿里云200+款云产品折上再折,满足多样场景的上云需求 活动规则
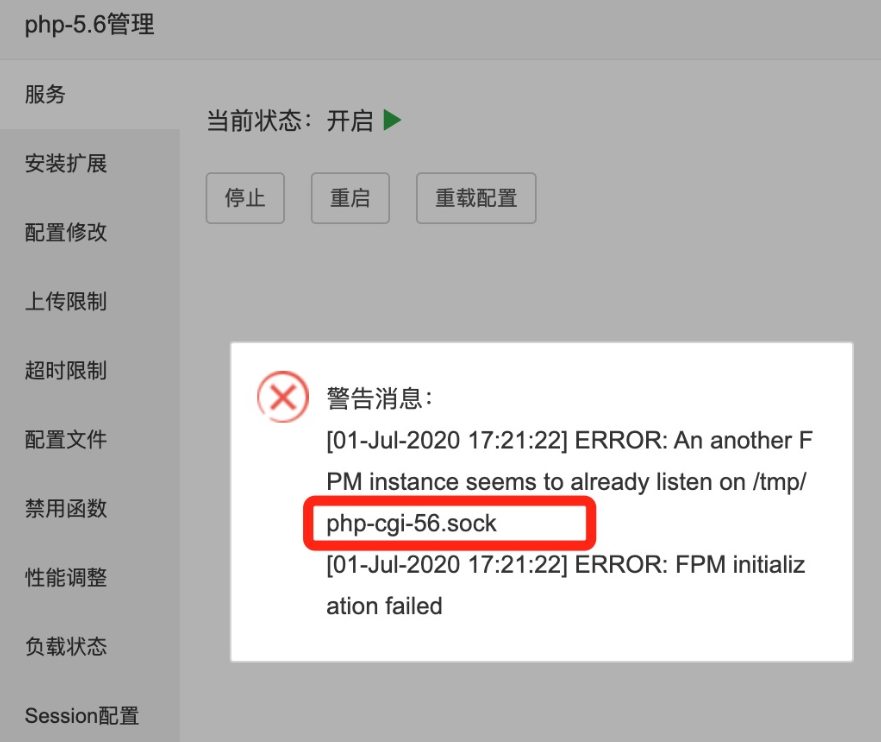
解决方法:将这个路径下的文件删除后再重启 /tmp/php-cgi-56.sock
进入ssh 执行以下命令再重启php
rm -f /tmp/php-cgi-56.sock具体不同的php版本,需要将以上命令的56更换为具体报错的php版本号,不能生搬硬套哦
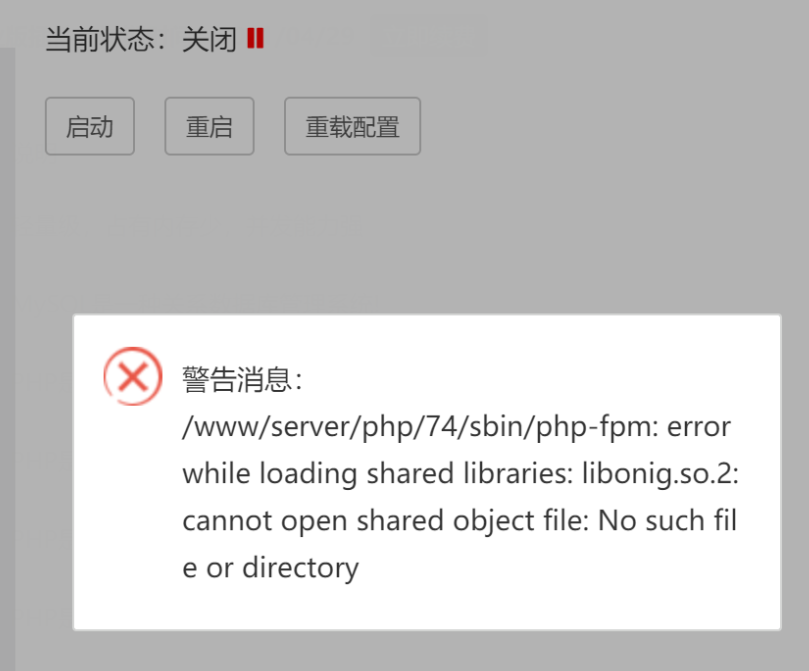
解决方法:进入ssh 执行这条命令 再尝试启动
yum install libsodium-devel sqlite-devel oniguruma-devel libwebp-devel libvpx-devel -y
解决方法:
/etc/init.d/php-fpm-72 stop /etc/init.d/php-fpm-72 start然后再启动试试
注意:以上的72,为php版本号,哪个版本的php启动不了,就将以上命令的72改为对应版本号
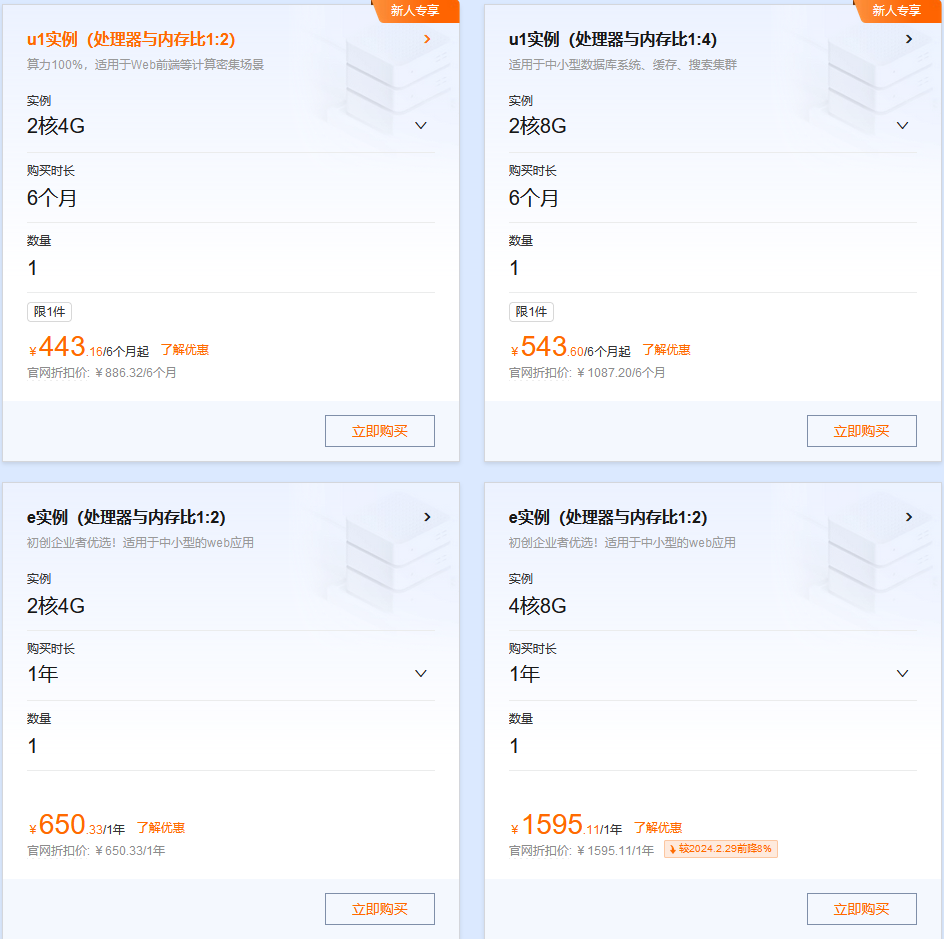
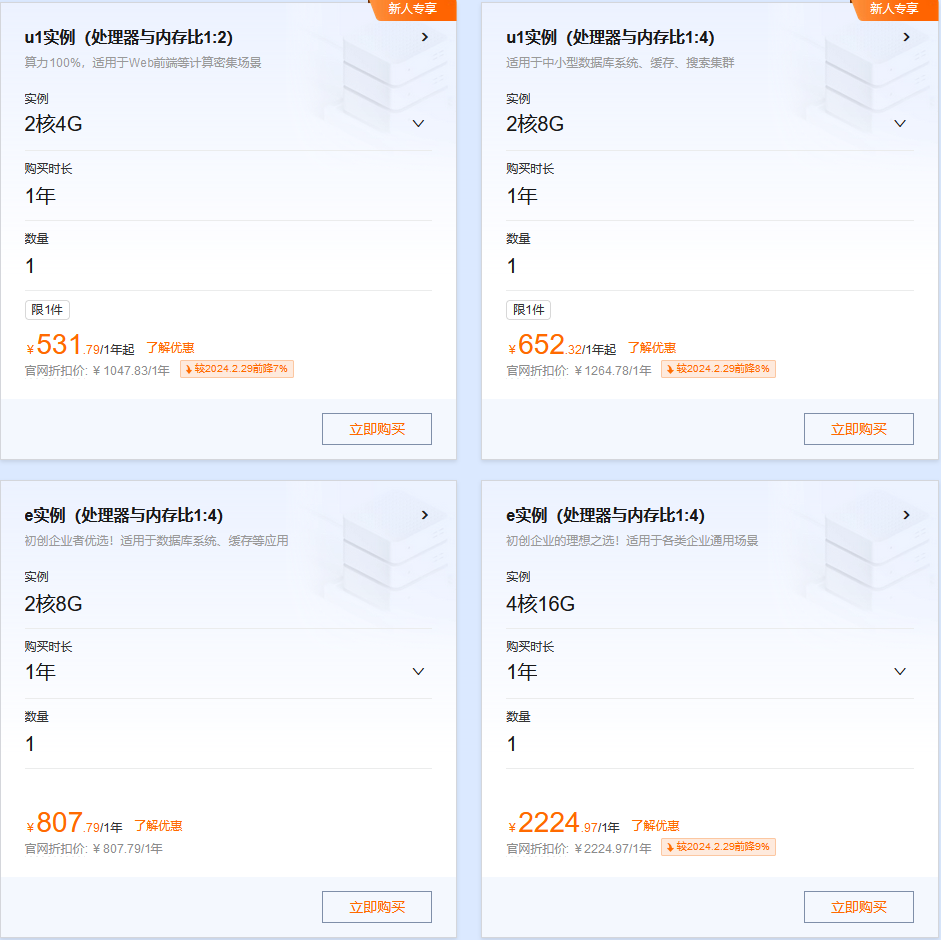
阿里云上云优惠聚集地,新人专享优惠价格,可叠加专享代金券购买价格更低。
折扣卷领取:https://www.aliyun.com/minisite/goods?userCode=fa2nbd3s


(1)折扣券不可用于购买产品提货券;
(2)99计划产品暂不支持折扣补贴券抵扣使用;
(3)折扣券必须先领取成功后方可使用;
(4)PC或者无线端订单最终是否支持折扣券请以下单页面实际情况为准;
(5)用户领取的折扣券有效期为15天,有效期内下单购买有效,15天后券自动失效作废。
 同价续费:参与本专区活动,享新购续费同价1次
同价续费:参与本专区活动,享新购续费同价1次

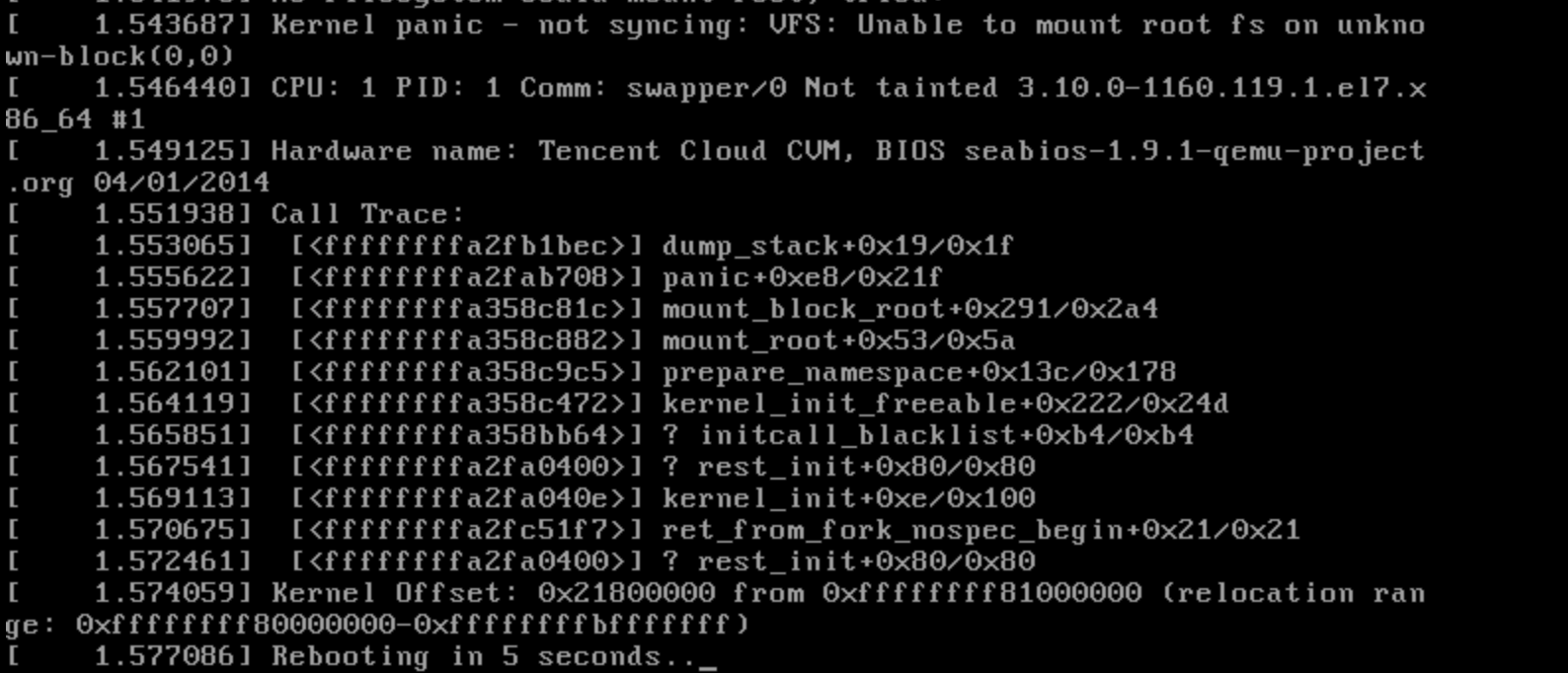
1. 系统启动失败,输出 VFS: Unable to mount root fs on unknow-block 可能是 initramfs 或 initrd 有问题,需要重新 生成 initramfs 或 initrd:。如下图所示:

mkdir -p /mnt/vm1
mount /dev/vda1 /mnt/vm1
mount -o bind /dev /mnt/vm1/dev
mount -o bind /dev/pts /mnt/vm1/dev/pts
mount -o bind /proc /mnt/vm1/proc
mount -o bind /run /mnt/vm1/run
mount -o bind /sys /mnt/vm1/sys
chroot /mnt/vm1 /bin/bash3.执行以下命令,重新生成 initramfs/initrd。
wget http://mirrors.tencentyun.com/install/cts/linux/cvmrescue_main.sh && chmod +x cvmrescue_main.sh && ./cvmrescue_main.sh -m rebuild_initramfs碰到域名解析失败的可以在 /etc/hosts 中配置 hosts 169.254.0.3 mirrors.tencentyun.com。
4.输出如下,表示 initramfs 或 initrd 新建成功。

5.参见 使用救援模式,退出救援模式,启动系统。
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文介绍如何使用iostat、iotop工具查看I/O负载情况。
iotop是一个用来监视磁盘I/O使用状况的top类工具,可以从进程纬度查看磁盘IO负载。
执行如下命令,安装iotop。
yum install iotop执行如下命令,查看I/O负载。
iotop -k -n 5 -d 3-b:记录到日志。
-k:以KB为单位显示。
-n:统计次数。
-d:统计时间间隔。
显示结果如下。
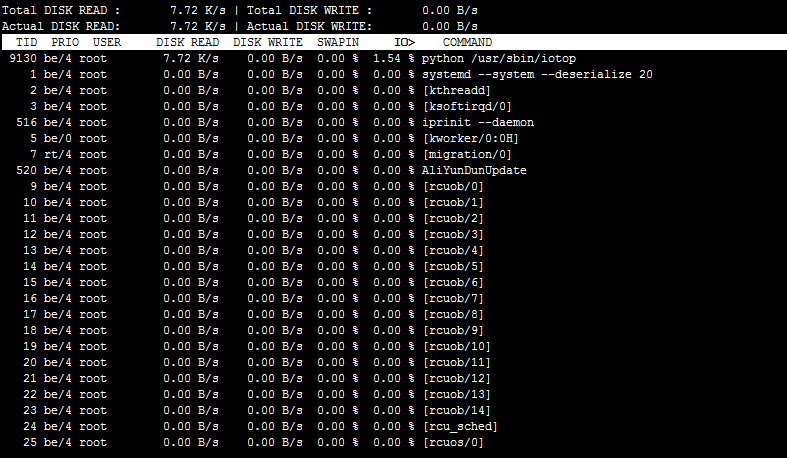
显示结果参数说明如下,更多参数说明,可执行iotop -h查询。
DISK READ:该进程读I/O带宽。
DISK WRITE:该进程写I/O带宽。
SWAPIN:磁盘的交换使用率。
IO:该进程的 I/O 利用率,包含磁盘和交换。
使用iotop排查分析,发现kjournald进程占用了大量I/O资源。
该问题通常是由于.ext3文件系统设置的Journal size太小导致。
kjournald进程是ext3文件系统进行I/O数据操作的内核进程,它在向磁盘内写入和读取数据时占用CPU和内存资源。当循环的向ext3文件系统写数据时,会使Journal size不断增大,到达设置的Journal size时,就会出现该问题。
远程连接Linux系统的ECS实例。
具体操作,请参见连接方式概述。
执行如下命令,查看相应分区的Journal size大小。
dumpe2fs /dev/xvda1 | grep Journal/dev/xvda1请替换为实际的分区。
系统显示类似如下,表示/dev/xvda1分区的Journal size为128M。
dumpe2fs 1.42.9 (28-Dec-2013)
Journal inode: 8
Journal backup: inode blocks
Journal features: journal_incompat_revoke
Journal size: 128M
Journal length: 32768
Journal sequence: 0x00010ffb
Journal start: 10953执行如下命令,修改Journal size大小。
mke2fs -J size=400 /dev/xvda1 请根据业务需要,修改size大小,/dev/xvda1请替换为实际的分区。
4K对齐指将符合4K扇区定义格式化过的硬盘,按照4K扇区的规则写入数据。4K对齐可以使簇与扇区相对应,保证了磁盘读写效率,以提高I/O性能。
本操作介绍如何通过以下脚本对磁盘进行格式化并自动配置4K对齐。
运行此脚本会自动格式化所有数据盘,如果非新购数据盘,请在操作前,确认已对相关数据盘进行数据备份。具体操作,请参见创建一个云盘快照。
使用root用户远程连接Linux系统的ECS实例。
具体操作,请参见连接方式概述。
下载auto_fdisk.zip压缩包后解压,将解压后脚本并上传到目标服务器。
依次执行如下命令,为脚本添加执行权限,然后运行脚本。
chmod +x ./auto_fdisk.sh
./auto_fdisk.sh